
HBase의 특징
Apache HBase – Apache HBase™ Home
Welcome to Apache HBase™ Apache HBase™ is the Hadoop database, a distributed, scalable, big data store. Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions
hbase.apache.org
HBase 저장 아키텍처
▪ HMaster : HRegionServer의 모니터링을 담당
▪ HRegionServer : 데이터를 분산저장하는 기능 수행
▪ HDFS : 데이터 저장과 복제기능 수행. 실제 저장소
▪ Zookeeper : HMaster의 위치 정보 유지 및 마스터 선출 담당
-
RegionServer는 영역(region)이라는 단위로 데이터를 분산하는 기능을 담당한다. Region이란 정렬된 데이터를 저장한 큰 테이블을 정렬키(Row Key) 범위로 나눈 것을 말한다. 각 Region이 저장하는 정렬키 범위는 Meta Region이라는 곳에 저장한다. 그리고 Meta Region의 위치는 Root Region에 저장된다. 하나의 Region Server는 Root Region, Meta Region, Region이 계층적으로 구성된 트리 형태로 정보를 저장한다
-
Region은 Region Server마다 n개의 Region을 가질 수 있으며, 하나의 Region은 일정 크기 이상 커지면 분리된다.
-
HBase는 쓰기 작업을 할 때 우선 WAL(Write Ahead Log:HLog)에 데이터를 저장한다. 이것은 RDB의 Commit Log와 유사한 개념이다. 이후 zookeeper는 저장이 가능한 Region Server를 찾아서 WAL에 저장된 데이터를 Memstore라고 하는 저장소에 저장한다. Memstore에 저장된 데이터가 가득차게 되면 Zookeeper는 HFile이라고 하는 HDFS 상의 파일에 Flush한다.
Region server 장애발생시 복구
1) HMaster가 장애를 감지하고, 장애서버의 Region을 다른 Region Server가 대체하여 서비스하도록 알린다.
2) 알림을 받은 Region Server는 먼저 WAL(Write Ahead Log)를 읽어서 그 영역의 Memstore를 복구 한다.
3) Memstore 복구가 완료되면 HMaster는 Region의 위치 정보를 저장하고 있는 Meta Region 정보를 수정하여 해당 Region에 대한 서비스를 재개한다.
4) 디스크에 저장되어 있는 Region 의 데이터들은 HDFS에 의해 새로 복구되고 복제된다.
HFile Compaction
Minor Compaction
▪ 정해진 기준에 따라 작은 크기의 HFile을 병합하여 하나의 HFile을 만드는 과정
▪ 기준 : 저장소의 최대/최소 HFile 개수, 최소크기, 최대 크기
▪ 삭제된 Row, 오래된 버전도 그대로 Merge됨
Major Compaction
▪ 저장소의 모든 HFile을 병합하여 하나의 HFile을 생성함.
▪ 삭제된 Row, 오래된 버전은 삭제됨.
HFile의 기본 블록 크기 : 64KB
▪ 블록 크기를 줄이면 랜덤 접근에 유리함.
▪ 블록 크기를 늘리면 순차 접근에 유리함.
데이터 일관성 보장
▪ HMaster가 분산된 복제 데이터 사이의 일관성을 보장
- Cassandra는 성능을 우선시할 때 일관성이 보장되지 않을수 있음(조절가능한
일관성)
Hadoop과의 밀접한 통합
▪ HDFS를 저장소로 사용할 수 있음.
▪ MapReduce나 Hive, Tajo 등과 효과적으로 통합
HBase의 사용
언제 사용이 적합할까?
이벤트 로깅
▪ 로그 분석 방식에 따라 Wide Row가 될 수도 있음
- NOSQL 종류에 따라 조금씩 차이가 있을 수 있지만 한개의 Row에 수십만~수천만개의 컬럼이 추가될 수 있음.
사례1) 날짜를 Row Key로 사용하고 Machine Code와 일련번호를 결합하여 컬럼키로 사용하면 컬럼키로 정렬됨
사례2) 날짜를 Machine Code와 날짜정보를 결합하여 Row Key로 설정 --> Machine 별로 로그를 분석할 일이 많은 경우
카운터, CMS(Content Mgmt, System), Blog
적절하지 않은 사용?
ACID 트랜잭션이 요구되는 시스템
▪ 원자적 업데이트만을 지원하므로...
쿼리를 사용해 집계할 필요가 있는 시스템
▪CF 기반 nosql들은 자체 집계 기능이 없는 경우가 많음
▪ Application Side에서 집계를 직접 하거나, Hadoop과 연동하여 Hive,Tajo 등의 SQL on Hadoop을 이용하면 집계가 가능하지만 실시간 응답보다는 batch 처리에 가깝다.
Prototype이나 기술 검토 목적
▪ Rowkey나 Column Key 변경될 가능성이 큰 시스템
▪ 자주 변경될 가능성이 큰 시스템에는 적절치 않다.
- 물리적인 저장 방식이 변경되는 것은 큰 문제를 야기시킨다. - 물리적인 저장 방식의 변경은 쿼리 변경을 유발시킬 수 있다.
기본명령어
▪ create '<테이블명>', '<CF명>', '<CF명>', ...
- CF명(Column Family명)은 여러개를 등록할 수 있음.
• 컬럼을 추가할때는 등록된 CF명만 사용할수 있음
- Column Family 수준으로 옵션을 지정하고 싶다면 마지막에 다음과 같이 추가할 수 있음.
• create 'test2', {NAME=>'cf1', VERSIONS=>1, TTL=>86400 }
▪ list
- 테이블 목록을 조회할 수 있음.
▪ disable '<테이블명>'
- 테이블을 비활성화함.
- 액세스가 불가함.
▪ enable '<테이블명>'
- 테이블 활성화함.
▪ drop '<테이블명>'
- 테이블을 삭제함
- disable 된 테이블만 삭제가 가능함.
▪ is_enabled '<테이블명>'
- 활성화된 테이블인지 확인함.
▪ disable_all '<테이블명>' enable_all '<테이블명>'
- 테이블명으로 정규식 사용. 한꺼번에 활성화, 비활성화함.
▪ describe '<테이블명>'
- 테이블에 대한 상세정보를 리턴함.
▪ alter '<테이블명>', 옵션=>값, 옵션=>값
- 컬럼패밀리 삭제
• alter 'test1', NAME=>'cf1', METHOD=>'delete'
- 컬럼패밀리 추가/수정
• alter 'test1', NAME=>'cf2', VERSIONS=>0
- 테이블 옵션 설정
• alter 'test1', METHOD=>'table_att', MAX_FILESIZE=>'134217728'
▪ exists '<테이블명>'
- 테이블의 존재 여부 확인
▪ put '<테이블명>', '<rowid>', '<cf명:컬럼명>', '값'
- put 'test1', 'key1', 'cf1:a', '1111'
• test1 테이블의 key1 Row에 cf1:a 컬럼 값으로 '1111'값을 저장
- put 명령어는 데이터를 추가/수정할 때 모두 사용됨.
▪ get '<테이블명>', '<rowid>'
- get 'test1', 'key1'
- get 'test1', 'key1', 'cf1'
- get 'test1', 'key1', 'cf1:a'
▪ delete '<테이블명>', '<rowid>', '<cf명:컬럼명>', '<Timestamp>'
- delete 'test1', 'key1', 'cf1:a'
- deleteall 'test1', 'key1'
• Row 전체 삭제
HBase의 핵심, scan 명령어
HBase는 row key가 partial scan이 가능함.
1) 어떻게든 row key로 쿼리될수있도록 모델링한다.
2) column family 설정
3) 필요하다면 index table 생성한다.
HBase의 강점 중 하나는 강력한 필터링 기능. 자세한 필터링 기능에 대한 내용은 다음을 참조.
https://www.cloudera.com/documentation/enterprise/5-5-x/topics/admin_hbase_filtering.html
HBase Filtering | 5.5.x | Cloudera Documentation
When reading data from HBase using Get or Scan operations, you can use custom filters to return a subset of results to the client. While this does not reduce server-side IO, it does reduce network bandwidth and reduces the amount of data the client needs t
www.cloudera.com
만약 timestamp를 row key라고 정하자. 한 서버에만 집중 write되는 현상(hotspot)이 일어남. 그러므로 row key를 무었으로 정하느냐가 매우 중요하다.
▪ scan '<테이블명>', { 옵션 } // 필터링 기능들
- scan 'test1'
- scan 'test1', {COLUMNS=>'cf1:a'}
- scan 'test1', { FILTER => "ValueFilter(=,'substring:asa')" }
- scan 'test1', {COLUMNS => ['cf1:a', 'cf1:b'], LIMIT => 3, STARTROW => 'key2'}
▪ count '<테이블명>'
- count 'test1'
▪ truncate '<테이블명>'
- truncate 'test1'
- disable -> drop -> recreate
HBase Java client
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String tblName = "orders";
String cf1 = "client";
String cf2 = "product";
Configuration config = HBaseConfiguration.create();
config.clear();
config.set("hbase.master", "s1.test.com");
config.set("hbase.zookeeper.quorum", "s1.test.com");
config.set("hbase.zookeeper.property.clientPort", "2181");
//---Query Data
HTable table = new HTable(config, tblName);
Scan s = new Scan();
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
for (KeyValue kv : r.raw()) {
System.out.println("row:" + new String(kv.getRow(), "utf-8") + "");
System.out.println("family:" + new String(kv.getFamily(), "utf-8") + ":");
System.out.println("qualifier:" + new String(kv.getQualifier(), "utf-8") + "");
System.out.println("value:" + new String(kv.getValue(), "utf-8"));
System.out.println("timestamp:" + kv.getTimestamp() + "");
System.out.println("-------------------------------------------");
}
}
table.close();
}HBase shell방식으로 접근하게 되면 데이터 insert, 데이터 read 등 하기 매우 까다롭다. 별도의 interface로 만들어 사용하는게 좋음.
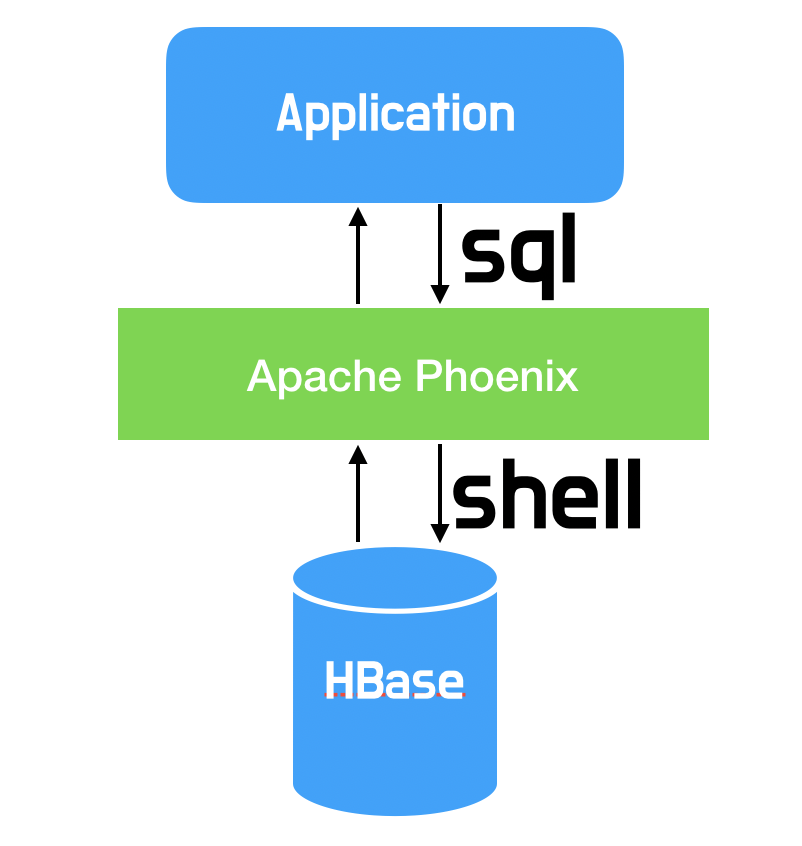
Apache Phoenix
Hbase의 기존 shell방식이 너무 힘듦. Phoenix를 통해 익숙한 sql을 사용가능.
Overview | Apache Phoenix
Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds: the power of standard SQL and JDBC APIs with full ACID transaction capabilities and the flexibility of late-bound, schema-on-
phoenix.apache.org
▪ Hbase에서 SQL구문을 사용할 수 있게 해주는 Hadoop Ecosystem 요소중 하나
- Hbase의 클라이언트 처럼 작동함.
- JDBC 사용 가능
▪ 다음의 기능 지원
- Secondary Index, JOIN, SubQuery, Sequence
- Salted Table , Array, Dynamic Column
- Paged Query
Secondary Indexing setup
Index처리를 원래 테이블에만 쓰기하더라도 두 군대 쓰기가 이루어지도록 hbase-site.xml 셋팅(wal : write ahead load)
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>- HBase 에서는 primary row key 에 의해 정렬된 단일 인덱스만 존재.
- Primary row key 이외 레코드 접근은 full scan으로 인해 위험할 수 있음.
- Secondary indexing을 통해 range scan을 가능하게 함으로써 row key를 대체.
Apache Phoenix의 index는 일반적인 b-tree index와 다르게 index table을 참조하여 index한다.
Phoenix의 단점
Phoenix로 인해 만들어진 구조는 성능에 영향이 크기 때문에 hbase shell로 면밀히 살펴볼 필요 있음.
JOIN과 GROUP BY는 Phoenix side에서 수행하기 때문에 성능상 이슈가 있음. 많은 메모리 사용이 요구됨.
메모리가 부족하면 phoenix가 shutdown됨.
'빅데이터 > nosql' 카테고리의 다른 글
| NoSQL강의) mongoDB 개요 및 설명 한페이지에 끝내기(mapReduce, aggregate 예제 포함) (407) | 2019.07.23 |
|---|---|
| NoSQL강의) Document Database 개요 및 설명 (375) | 2019.07.23 |
| NoSQL강의) DynamoDB 개요, 특징 및 설명 (392) | 2019.07.23 |
| NoSQL강의) Column Family Database 개요 및 설명 (390) | 2019.07.22 |
| NoSQL강의) Redis 개요, 기본사용법, command 설명 및 Jedis 예제 (251) | 2019.07.22 |
| NoSQL강의) Key-value Database 개요 및 설명 (267) | 2019.07.22 |



