
모델링 example 1 - Log 데이터
저장요구조건
- machine_id , log_time, log_text
- machine 100EA, 1초당 로그 1건씩, 로그는 일반 텍스트
Case 1 : 별도의 PK를 부여한다면?
CREATE TABLE log1 (
uid int,
machine_id varchar,
log_time timestamp,
log_text varchar,
PRIMARY KEY (uid)
);→ 특정머신의 로그만 조회하는 것이 불가. 의미없는 모델.
▪ Log성 테이블은 Primary Key를 단일 값으로 설정하는 것이 힘들다. machine_id를 단일 primary key로 설정하면 machine_id가 Row Key가 되는데, 이 경우 시계열 데이터를 저장할 수 없게 된다.
▪ 별도의 UUID와 같은 고유값을 Row Key로 지정하고 값을 저장하는 것은 가능하지만, 이 경우 Row Key가 아닌 별도의 컬럼값으로 조회를 하려면 secondary index를 지정해주어야 한다. 하지만 EQ 쿼리만 가능하며, Range Query는 불가능하다.
▪ 추가적으로 secondary index를 지정해주는 것은 추가적인 부하를 발생시킨다. 가능하다면 저장할때 물리적으로 정렬되어 저장되는 것이 바람직하다.
Case 2 : machine_id를 PK로?
CREATE TABLE log2 (
machine_id varchar,
log_time timestamp,
log_text varchar,
PRIMARY KEY (machine_id)
);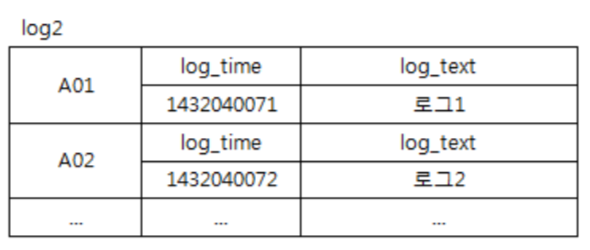
→ 불가능. 단일 Row key로는 하나의 Row만 입력가능하기 때문.
Case 3 : 복합 Primary Key사용
복합 primary key는 순서가 중요
Row Key로는 EQ,IN 쿼리만 가능, Column Key로는 Range Query 가능
CREATE TABLE log31 (
machine_id varchar,
log_time timestamp,
log_text varchar,
PRIMARY KEY (machine_id,log_time) // machine_id를 우선 primaryKey로 할 경우
);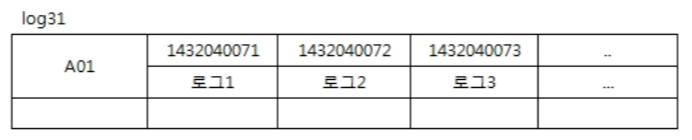
→ machine 별 row가 생성되기 때문에 1 row가 끝없이 길어짐
▪ Row가 machine의 갯수만큼 100개만 생성됨.
▪ 하나의 Row에 초당 하나씩 컬럼이 생성되어 Ultra Wide Row가 작성됨. --> 적절치 않음
▪ 특정 machine의 모든 시간대 로그 조회 --> 가능함. Row하나를 조회하는 것임
▪ 특정 날짜의 모든 machine 로그 조회 --> 가능함.
CREATE TABLE log31 (
machine_id varchar,
log_time timestamp,
log_text varchar,
PRIMARY KEY (log_time,machine_id) // log_time을 우선 primaryKey로 할 경우
);
→ 시간별 정렬 불가
▪ Row 하나당 100EA의 장비 갯수만큼 컬럼이 생성됨.
▪ 특정 날짜의 모든 Machine 로그를 조회 --> 불가능 Row Key로는 Range Query가 불가능함.
▪ 특정 machine의 모든 시간대 로그 조회 --> 가능함. Allow Filtering 옵션을 사용해야 함.
Case 4 : machine_id, log_date(날짜)를 row key로 지정. log_time을 column key로 사용
CREATE TABLE log4 (
machine_id varchar,
log_date varchar,
log_time timestamp,
log_text varchar,
PRIMARY KEY ((machine_id,log_date),log_time)
);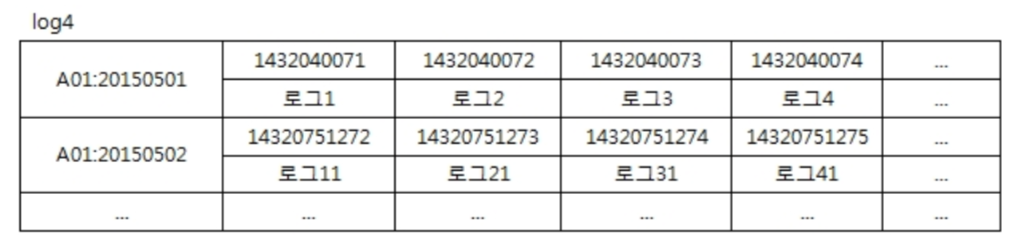
→ Row Key = machine_id + log_date
▪ 하나의 Row에 초당 1건씩 86400개의 컬럼이 추가됨. --> 적당한 Wide Row
▪ log_time으로 Range Query 가능함. 조회결과가 양이 많을 수 있으므로 조회시 Allow Filtering 옵션을 부여해야 함.
▪ 특정 머신별 날짜별 조회에 유용한 형태
– select * from log4 where machine_id='A01' and log_date='20150501';
모델링 example 2 - Music service
저장요구조건
Entity 정보
■ Entity
▪ Artist
▪ Song
▪ Album
■ 관계
▪ 한사람의 아티스트는 여러개의 곡의 가수가 될 수 있다.
▪ 한 앨범에 여러개의 곡이 수록될 수 있다.
쿼리 결과 디자인 고려사항
▪ 고려사항
- 읽기 성능이 우선이며, 쓰기 성능은 중요하지 않다.
- 고도의 일관성이 요구되지 않는다.
▪ 조회화면
- 아티스트 정보 조회
• 아티스트의 곡명 리스트를 한번에 조회할 수 있도록 설계되어야 함.(조회빈도 높음)
• 한번 값이 저장되면 자주 변경되지 않음
- 곡명 조회
• 곡명으로 조회하는 경우 아티스트 정보(이름)와 앨범정보(앨범명)를 한번에 조회할 수 있어야 함.(조회빈도 높음)
- 앨범명 조회
• 앨범명으로 조회시 관련 곡 목록 정보를 조회함(조회빈도 낮음)
▪ 아티스트 정보 조회
▪ 곡명 조회
▪ 앨범정보 조회
모델링
ARTIST 테이블
CREATE TABLE artist(
artist_id uuid,
artist_name varchar,
email varchar,
songs list<text>,
PRIMARY KEY (artist_id)
);
CREATE INDEX idx_artist ON artist(artist_name);→ artist_id가 Primary Key
SONG 테이블
CREATE TABLE song(
song_id uuid,
title varchar,
artist_id uuid,
artist_name varchar,
album_id uuid,
album_title varchar,
PRIMARY KEY (album_id, song_id)
);
CREATE INDEX idx_song_title ON song(title);
→ album_id기본정보와 함께 수록된 곡을 빠르게 조회 가능
→ song_id를 기반으로 곡의 정보를 빠르게 조회 가능
→ 곡명으로 조회가능해야 함
• title 에 대한 Secondary Index로 해결
→ 앨범 정보 조회시 곡리스트 조회
• 2번의 쿼리로 조회함. album_id로 곡을 조회할 수 있어야 함.
• album_id를 Row Key로 설정하고, song_id를 Column Key의 일부로 설정함.
→ 한곡만 조회하려면 song_id로도 가능하지만, album_id(Row Key)와 조회할 때 더 좋은 성능을 냄.
• song_id로만 조회하려면 allow filtering 옵션 추가해야 함
ALBUM 테이블
CREATE TABLE album(
album_id uuid,
album_title varchar,
pubdate timestamp,
PRIMARY KEY (album_id)
);
CREATE INDEX idx_album_title ON album(album_title);카산드라에 대한 개요 및 설명 → https://blog.voidmainvoid.net/235
NoSQL강의) Cassandra 개요 및 설명
특징 Peer to Peer - Multi Master Model(Master-Slave 구조가 아님) - 새로운 노드의 추가를 통해 수평적 확장이 손쉬움 - DHT(Disgtributed Hash Table) 기반의 링 토폴로지 지원 - 데이터의 분산과 장애 극복..
blog.voidmainvoid.net
'빅데이터 > cassandra' 카테고리의 다른 글
| 아파치 카산드라 살펴보기, 설명, 기본 개념 (0) | 2022.02.03 |
|---|---|
| 카산드라 TTL에 따른 데이터 삭제 정리 (0) | 2022.01.20 |
| Datastax의 Cassandra Sink Connector(JSON field) 적재 설정 (0) | 2021.12.16 |
| 카산드라 모델링 분석하기 좋은 테이블 구성하기 (0) | 2021.11.11 |
| macos에서 카산드라 테스트 방법 (0) | 2021.11.03 |
| NoSQL강의) Cassandra 개요 및 설명 (250) | 2019.07.22 |



