출처 : slideshare-Kafka Streams vs. KSQL for Stream Processing on top of Apache Kafka
Kafka는 Bigdata를 처리하고 운영함에 있어서 필수불가결하다. 이미 많은 IT기업들(카카오, 네이버 등)에서는 kafka로 동작하는 실서비스를 운영하고 있으며 그에 대한 know-how도 상당히 많이 공유되고 있다.
Kafka는 단순히 produce, consumer 구조로 사용가능하지만, KSQL이나 kafka stream을 사용하여 더욱 효과적이고 유연하게 데이터를 조작할 수 있다. 이번 포스팅에서는 KSQL과 Kafka stream에 대해서 소개하고 차이점도 알아보는 시간을 가지려고 한다.
KSQL
KSQL은 streaming SQL 엔진으로서 SQL문법으로 real time application을 작성할 수 있다.
Kafka stream
Kafka stream은 library로서 Java나 Scala로 real time application을 작성할 수 있다.
KSQL과 Kafka stream을 사용하는 대상은?
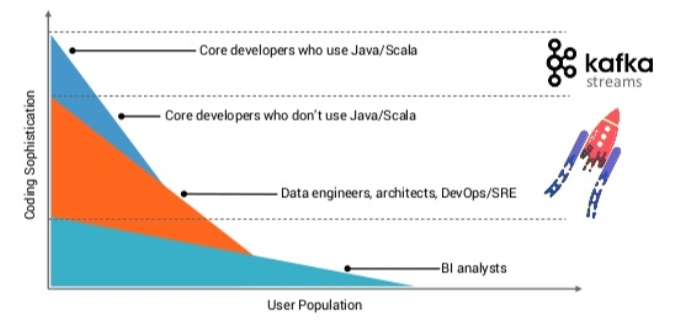
위 그래프에서 볼 수 있는것 처럼 Kafka stream은 좀더 개발에 능숙한 개발자를 위해 만들어졌다. Java나 Scala를 통해 개발할 수 있으면 Kafka stream을 사용하면 된다. 반면 KSQL은 Java나 Scala에 친숙하지 못한 개발자나 혹은 데이터엔지니어, 아키텍트, DevOps, SRE 직무의 개발자들에게 좀더 유용하다.
KSQL과 Kafka stream 사용방법
KSQL은 SQL문법으로 아래와 같이 작성할 수 있다.
CREATE STREAM fraudulent_payments AS
SELECT * FROM payments
WHERE fraudProbability > 0.8
Kafka stream은 아래와 같이 scala 문법으로 작성할 수 있다.
object WordCountScalaExample extends App {
import org.apache.kafka.streams.scala.Serdes._
import org.apache.kafka.streams.scala.ImplicitConversions._
val config: Properties = {
val p = new Properties()
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-scala-application")
val bootstrapServers = if (args.length > 0) args(0) else "localhost:9092"
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers)
p
}
val builder = new StreamsBuilder()
val textLines: KStream[String, String] = builder.stream[String, String]("streams-plaintext-input")
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count()
wordCounts.toStream.to("streams-wordcount-output")
val streams: KafkaStreams = new KafkaStreams(builder.build(), config)
streams.cleanUp()
streams.start()
sys.ShutdownHookThread {
streams.close(Duration.ofSeconds(10))
}
}
KSQL과 Kafka stream의 유사점
- Enterprise support
- All you need is Kafka
- Run everywhere
- Elastic, scalable, fault-tolerant
- Kafka security integration
- Powerful processing
- Support streams&tables
- Exactly-once processing
- Event-time processing
- Does not run on Kafka brokers
KSQL과 Kafka stream의 다른점

가장큰 차이는 KSQL은 SQL문법을 쓰며, KSQL server가 존재해야한다는 것이고 Kafka stream은 JVM application으로서 따로 process가 작동한다는 점이다. 이는 사용성에 있어서 매우 큰 차이를 나타낸다. KSQL을 운영하기 위해서 server을 따로 구동시키고 운영이 필요하다는 점은 운영 부담이 늘어난다는 단점이 될 수 있다. 물론 Kafka stream으로 개발한 JVM application을 따로 운영하는것도 운영 부담중 하나이므로 기업의 환경이나 요구사항에 맞게 사용하는 것이 좋을 것으로 보인다.
'빅데이터 > Kafka' 카테고리의 다른 글
| Kafka의 KSQL 컨셉, 아키텍쳐, 용어, 커스텀 function 적용하는 방법 (0) | 2019.10.11 |
|---|---|
| 아파치 카프카 테스트용 data generator 소개 - ksql-datagen (0) | 2019.10.10 |
| KSQL - Docker을 사용한 KSQL server, cli 설치 및 실행 (0) | 2019.10.08 |
| [KAFKA]commitSync() 사용시 rebalance발동시 offset variable을 초기화 해야하는 이유? (0) | 2019.09.30 |
| Kafka consumer의 Automatic Commit은 중복이 생길 수 있다 (1) | 2019.09.25 |
| enable.auto.commit 일 때 Kafka consumer close() method 동작분석 (0) | 2019.09.02 |



