EMR노트북은 이미 생성된 EMR클러스터를 활용할 수 있게 만든 주피터 노트북입니다. EMR클러스터에 직접 인스턴스 접속하여 각종 빅데이터 처리를 해도되지만 주피터를 사용한다면 좀더 편리한 환경에서 R, Python 등을 사용할 수 있습니다. 오늘은 이전에 생성한 스파크 EMR클러스터에 노트북을 연결하여 사용해보는 시간을 가지도록 하겠습니다.
스파크만 가지고 있는 소규모 EMR클러스터 생성은 아래 링크에서 확인하실 수 있습니다. https://blog.voidmainvoid.net/351
소규모 스파크 사용을 위한 AWS EMR 클러스터 생성하기
AWS에는 EMR이라고 불리는 빅데이터 플랫폼이 있습니다. EMR을 통해 스파크, 하이프, HBASE, 플링크 등 다양한 오픈소스 도구 셋트를 생성할 수 있습니다. 온프로미스로 직접 구축하는 것에 비해 매��
blog.voidmainvoid.net
EMR 노트북 생성하기
EMR 관리형 Jupyter 노트북을 통해 실시간 코드, 설명 텍스트, 시각화 등을 사용하여 대화식으로 데이터를 분석할 수 있습니다. Hadoop, Spark 및 Livy를 실행하는 Amazon EMR 클러스터에 노트북을 생성하고 연결합니다. 노트북은 무료로 실행되고 클러스터와 독립적으로 Amazon S3에 저장됩니다. 클러스터 및 Amazon S3에 대한 표준 결제가 적용됩니다.
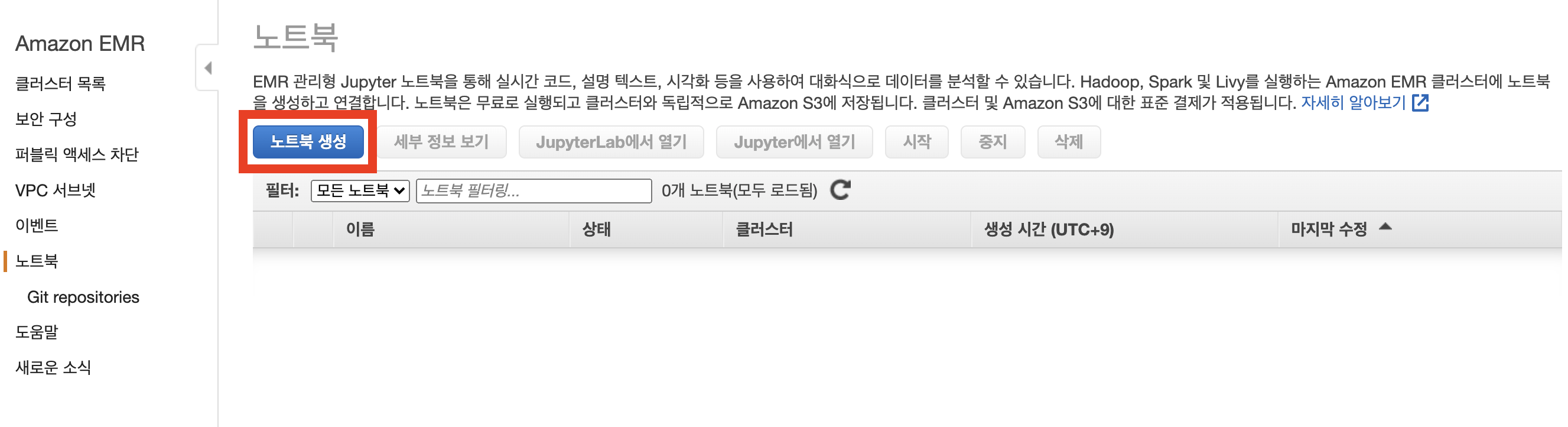

클러스터는 이전 포스팅에서 설정한 스파크만 설치된 EMR클러스터를 선택합니다. 노트북 위치는 EMR로 해도 되지만 S3 버켓으로 설정할수도 있습니다. 그리고 노트북 생성을 할 수 있습니다.
만약 S3오류가 발생한다면 타 서비스의 접근권한 이슈때문입니다. 아래와 같이 퍼블릭 엑세스 차단을 해제하면 에러가 발생하지 않습니다.


EMR 노트북 실행
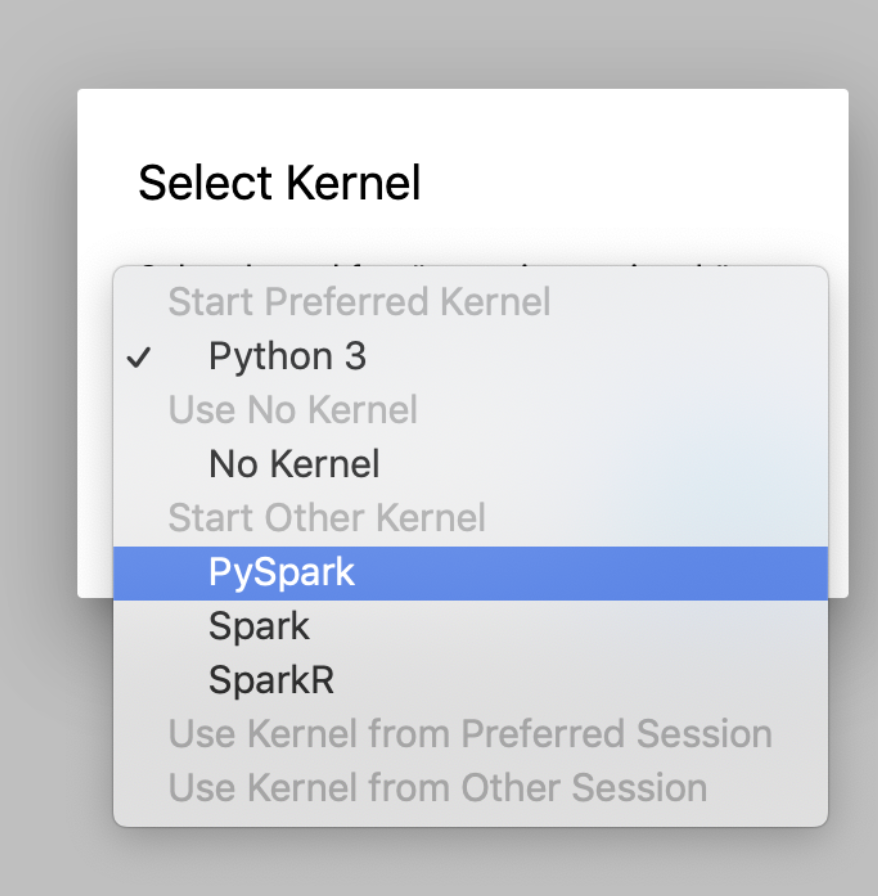
이제 JupyterLab을 켜서 spark를 실행해보겠습니다. JupyterLab에서 열기를 클릭하면 JupyterLab이 실행됩니다. pyspark를 실행할 것이므로 pyspark버튼을 눌러 새로운 노트북을 실행하도록 합니다.


'개발이야기 > AWS' 카테고리의 다른 글
| EMR 노트북에서 secret manager의 비밀키 조회하기 (0) | 2020.07.30 |
|---|---|
| AWS EMR사용시 사용자 지정 파이썬 라이브러리 설치 및 pyspark 사용 (0) | 2020.07.29 |
| AWS VPC지정을 위한 CIDR 형식 주소값 계산 방법 (0) | 2020.07.28 |
| 소규모 스파크 사용을 위한 AWS EMR 클러스터 생성하기 (2) | 2020.07.09 |
| aws ec2에 openJDK 1.8 설치하기 실습 예제 (0) | 2020.06.01 |
| EC2 SLA(서비스 계약 수준) 에 따른 uptime, downtime 시간 계산 (0) | 2020.05.28 |



