원문 : https://netflixtechblog.com/exploring-data-netflix-9d87e20072e3
Exploring Data @ Netflix
By Gim Mahasintunan on behalf of Data Platform Engineering.
netflixtechblog.com
어느 조직이든 빠르게 성장하는 가운데 다양한 데이터를 어떻게 저장하고 사용할지 결정하는 것은 매우 어려운 일이다. 넷플릭스에서는 스트림 데이터를 쉽게 사용할 수 있는 툴을 개발하고 활용하고 있다.
이번 포스트를 통해 Netflix Data Explorer 툴을 소개하게 되어 매우 기쁘다. Data Explorer는 엔지니어들에게 카산드라, 다이너마이트, 레디스 저장소에 있는 데이터를 빠르고 안전하게 접근 가능하도록 도와준다.
깃허브 주소 : https://github.com/Netflix/nf-data-explorer
역사
이 프로젝트는 다이너마이트(Dynomite) 저장소 사용자들을 위해 몇년동안 만들었다. 다이너마이트는 고성능 인메모리 저장소로서 레디스와 비슷하지만 데이터센터간 복제를 통해 고 가용성을 보장한다는 특징이 있다. 다이너마이트 사용자들에게 흔히 저장소의 데이터를 조회할 때 사용하는 CLI보다 더 쉬운 형태로 제공하고자 했다. 왜냐면 기존 CLI는 실수가 종종 발생할 뿐만 아니라 일부 기능은 성능에 좋지 않은 영향을 미칠때가 있기 때문이다.
프로젝트를 시작할 때 우리는 다른 저장소에도 적용가능할지 찾아보았다. 그러던 도중 우리(넷플릭스)의 최고의 성과물인 카산드라가 눈에 들어왔다. 카산드라 사용자들은 복제설정을 어떻게 하는지, 테이블에 적용할 적절한 압축 전략은 무엇인지에 대해 자주 물어봤었다. 우리는 카산드라 사용자들에게 이런 반복적인 질문들을 줄여주고자 하였고 사용자 경험을 높이는데 집중하였다.
이제 Data Explorer 기능들을 살펴보고 오픈소스 소프트웨어 커뮤니티를 통해 어떤 내용을 달성했는지 살펴보자.
멀티 클러스터 접근
우선, 사용자들은 간단히 웹 포털에 접근하여 저장소에 접근하고자 했다. 이를 통해 사용자의 생산성을 높이는데 기여하였다. 또한 상용에는 수백개의 클러스터가 있었는데 각 저장소별 접근 정책을 적용했다. Cluster Access Control Provider를 통해 OSS 환경에서도 사용자의 접근정보에 대응할 수 있게 만들었다.

스키마 디자이너
신규 카산드라 사용자에게 CREATE TABLE 명령어를 작성하는 것은 매우 어려운 일이다. 그래서 스키마 디자이너 개념을 도입하여 드래그 앤 드랍으로 새로운 테이블을 만들 수 있도록 만들었다.
스키마 디자이너는 primitive, collection 데이터 타입이 무엇인지 정의하고 어떤 파티션키와 클러스터링 컬럼을 사용할지 지정하여 새로운 테이블을 만들 수 있다. 그리고 디스크에 저장되는 저장소 레이아웃에 대한 정보를 제공 했다. 그리고 샘플 쿼리를 사용할 수 있도록 도와주며 압축 전략도 선택할 수 있으며 추가적인 고급설정도 가능하다.
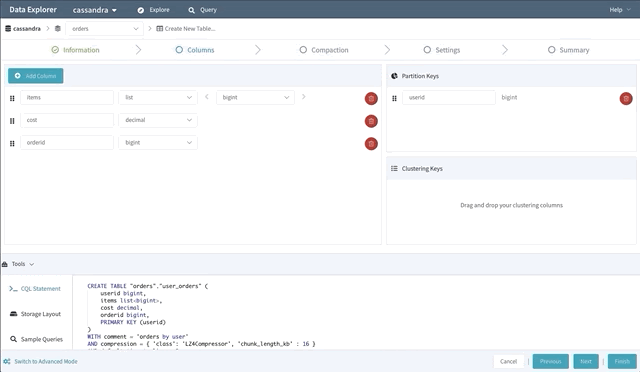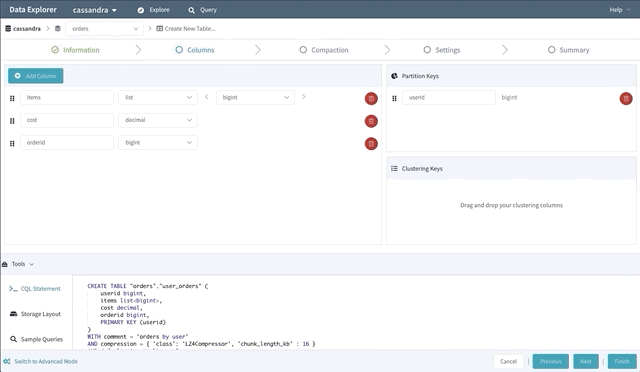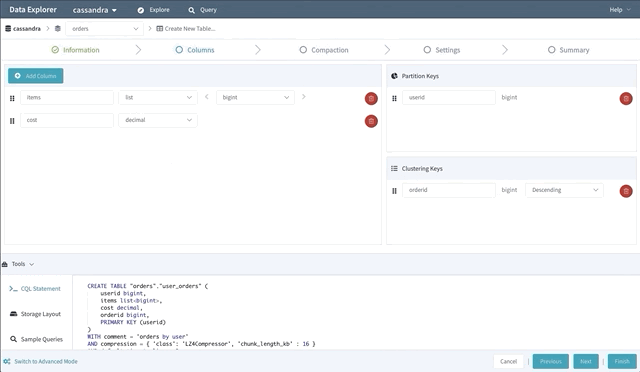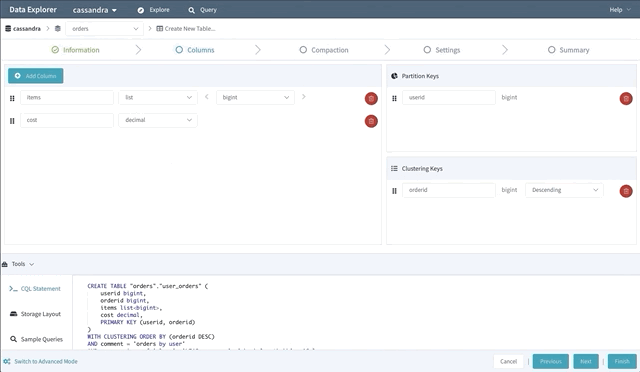
원하는 데이터 찾기
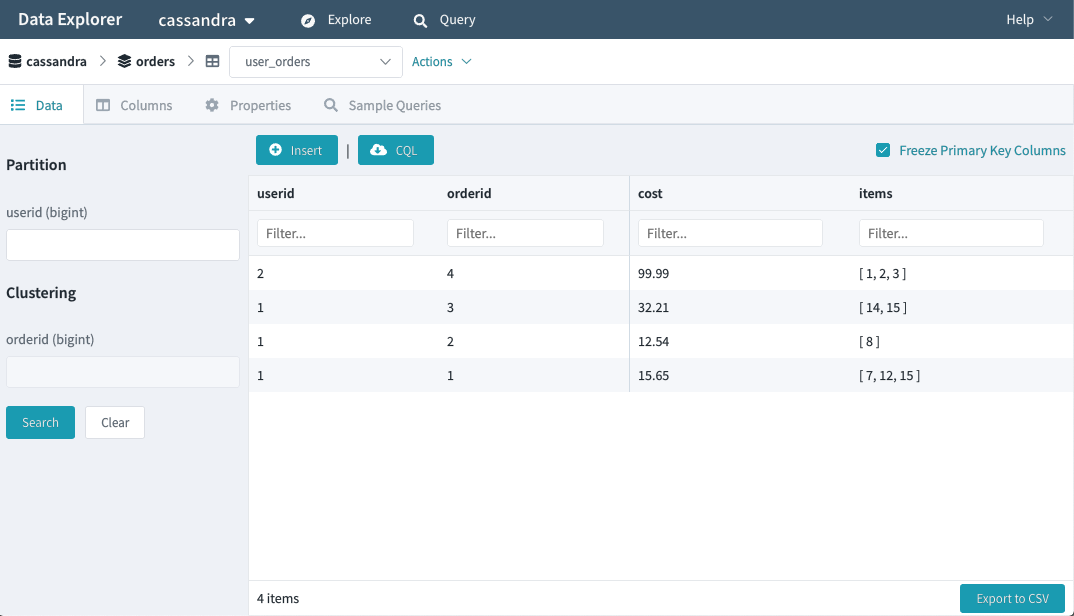
Explore 모드에서는 클러스터에서 필요한 쿼리를 날릴 저장소를 빠르게 찾을 수 있다. Explore 모드에서는 CRUD기능을 모두 제공하며 CSV로 데이터를 저장하거나 CQL insert statement를 다운받을 수도 있다. CQL을 추출하면 상용 환경의 데이터를 빠르게 테스트 환경으로 복제하여 사용할 수 있다.
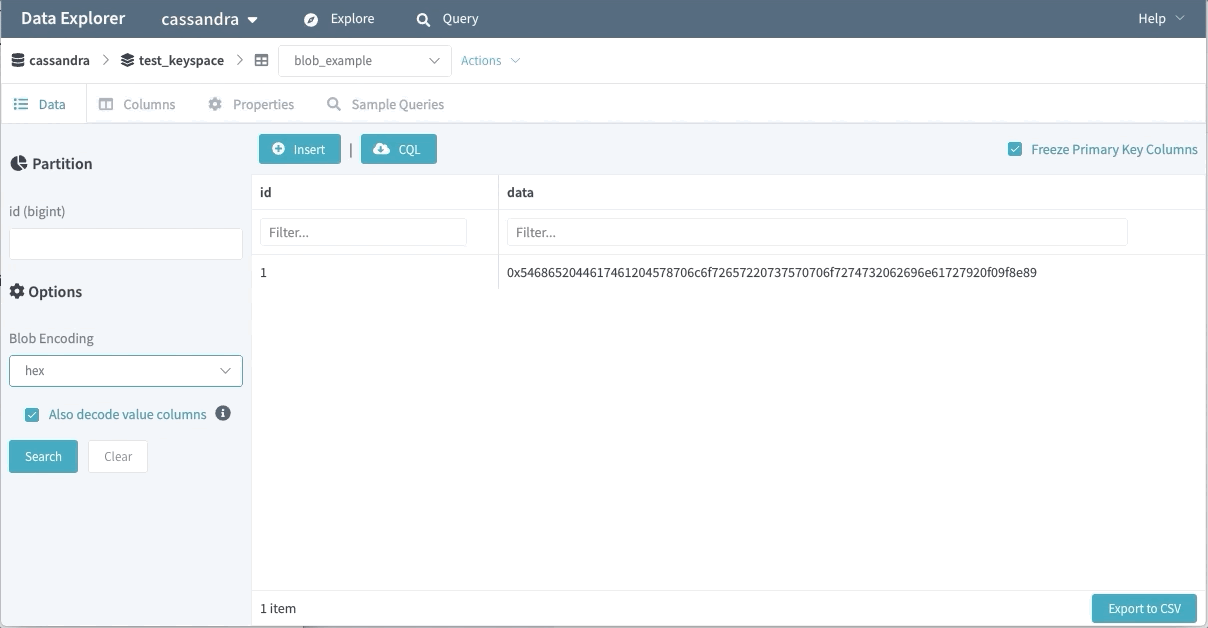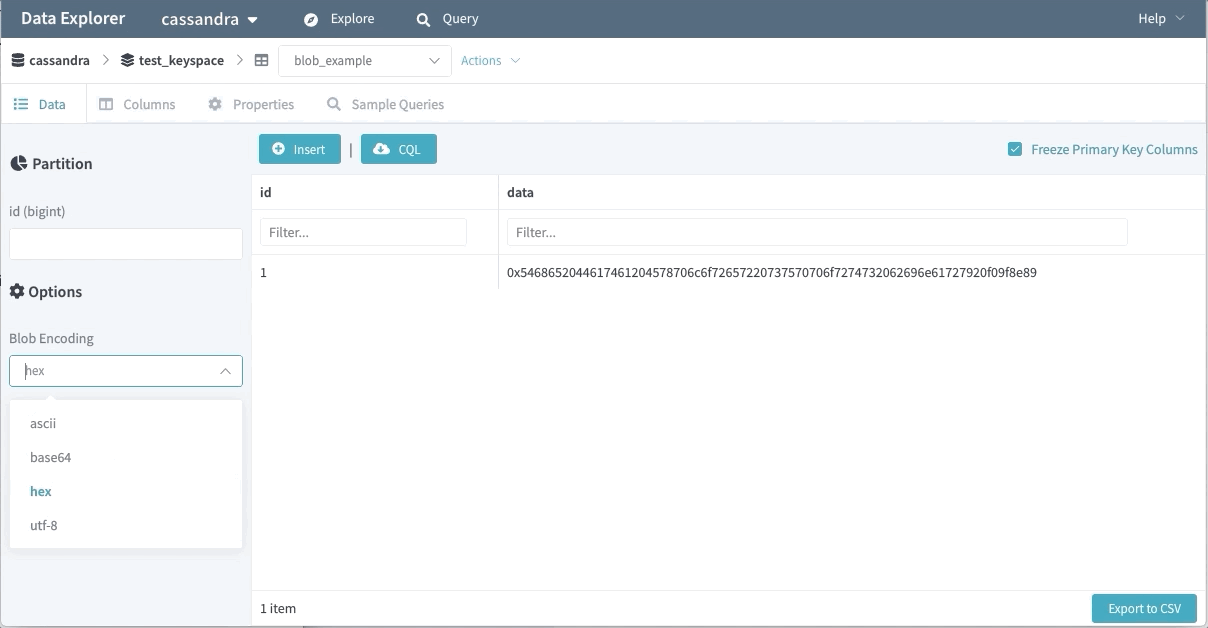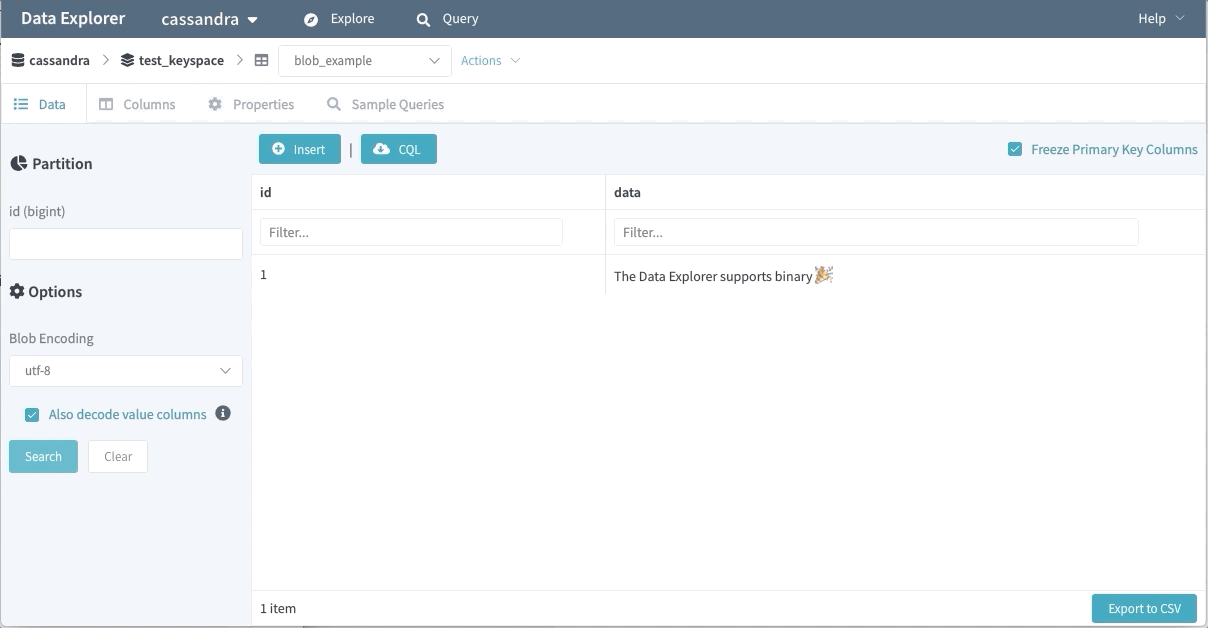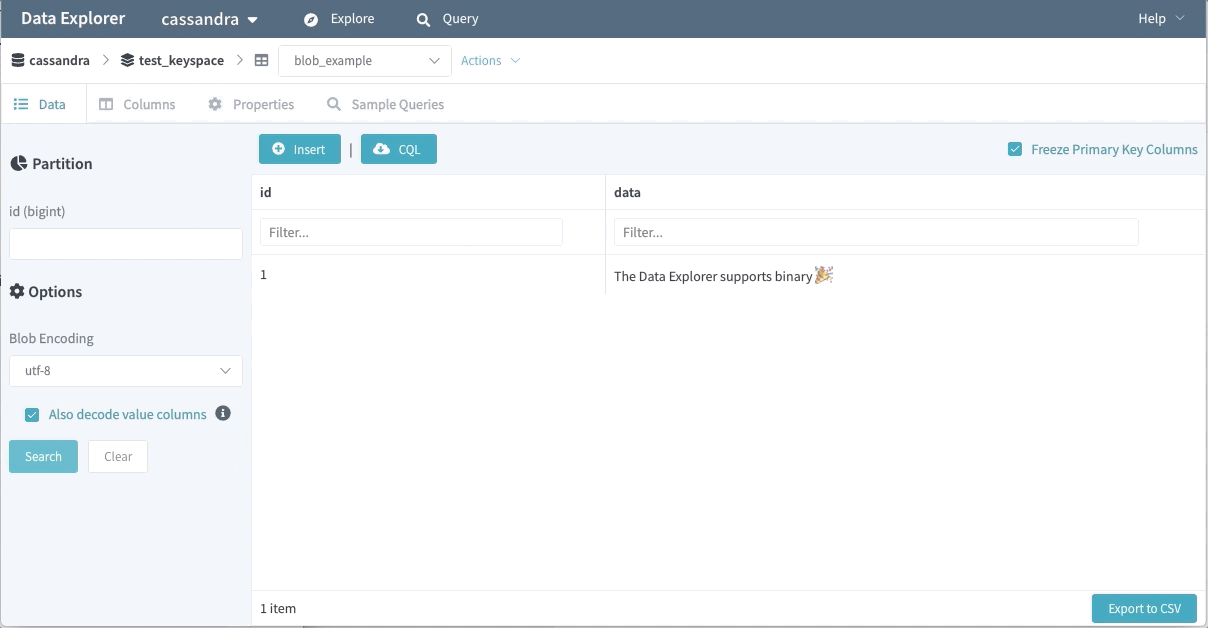
바이너리 데이터 지원
바이너리 데이터는 많은 엔지니어에게 사용되고 있다. Data Explorer는 바이너리 값을 기본으로 가져오지 않는데, 사용자는 어떤 방식으로 인코딩할지 지정하여 사용할 수 있다.
쿼리IDE
Explore모드에서는 쿼리를 실행할 수 있다. 하지만 많은 사용자들은 CQL을 제공받길 원했다. 쿼리모드에서는 많은 기능을 가진 CQL IDE를 제공하고 자동 완성기능을 통해 쉽게 데이터에 접근할 수 있다.

이런 IDE는 사용자로 하여금 실수하지 않도록 방어할 수 있는 여지를 가진다. 예를 들어 DROP TABLE과 같은 작업을 진행할 경우 추가적인 검증과정을 거쳐 실수가 발생하지 않도록 도와준다.
쿼리를 입력하면 최근에 접근한 쿼리를 확인할 수 있다. 매번 WHERE구문을 작성하면서 저번주에 무엇을 입력했는지 기억해낼 필요가 없다.
다이너마이트와 레디스 기능들
C*는 다양한 기능을 다이너마이트와 레디스 사용자에게 제공한다. 다이너마이트와 레디스는 호환된다는 점을 참고해서 알아보자.
키 스캔
우리는 사용자가 무심코 인메모리 저장소로 사용하는 레디스의 모든 키를 조회해서 메모리에 올리는 것을 방지하고자 했다. 우리는 SCAN 명령어를 통해 모든 클러스터에 문제가 생기지 않게 했다.
다이너마이트 수집 지원 기능
다이너마이트는 간단한 String 키 뿐만아니라 풍부한 데이터 타입들, 리스트, 해쉬, 셋 등을 지원한다. UI를 통해 이런 데이터들을 생성하고 수정할 수 있게 만들었다.

오픈소스소프트웨어 지원
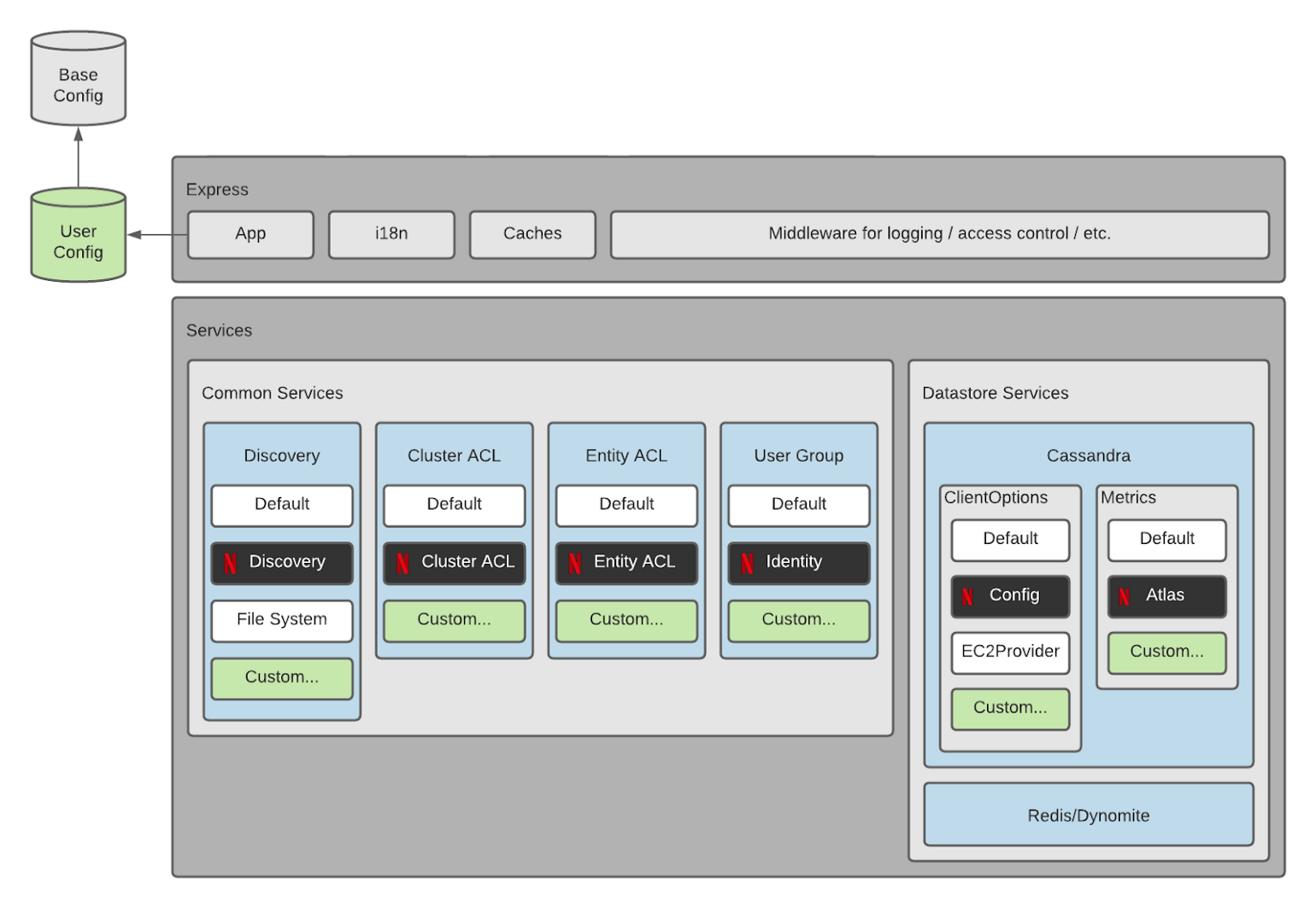
Data Explorer를 만들 때 넷플릭스 내부 뿐만 아니라 외부에서도 쉽게 사용할 수 있도록 만드는 것에 초점을 주었다. 내부에서는 다양한 오픈소스소프트웨어 환경을 지원하면서 어떻게 오픈소스를 만드는지 배워왔다. 이를 위해 필요에 따라 레이어 별로 개발함으로서 필요에 따라 커스텀 구성이 가능하도록 만들었다.
Data Explorer는 사용자가 검색, 액세스 제어 및 데이터 저장소별 연결 설정을 할 수 있도록 함으로서 오픈소스소프트웨어에 적합하게 설계되었다. 사용자는 빌트인 프로바이더를 선택하거나 커스텀 프로바이더를 선택할 수 있다.
다음 다이어그램은 서버 아키텍처를 보여준다. 서버는 타입스크립트로 만든 Node.js Express 애플리케이션으로 만들었으면 Vue.js로 프론트를 개발했다.
(중간 데모와 설정 사용부분은 글에서 제외함)
느낀점
우리 프로젝트를 살펴보고 잘 돌아가는지 알려주세요. 넷플릭스 Data Explorer에 공유해주시면 데이터를 사용하고 새로운 아이디어를 통해 영감을 줄 수 있기를 바란다.
'빅데이터' 카테고리의 다른 글
| 아파치 피노(apache pinot) 소개 (0) | 2022.04.22 |
|---|---|
| MLOps란 무엇인가? 영상 해설 (0) | 2022.03.17 |
| [번역]NVIDIA에서 정의하는 MLOps (0) | 2021.09.29 |
| 프로메테우스 지표 rate와 increase의 차이점 (0) | 2021.07.02 |
| 프로메테우스 promQL에서 without 또는 by 사용시 주의사항 (0) | 2021.07.01 |
| prometheus 자바 클라이언트로 지표 수집하기 (2) | 2021.06.29 |



