
다이나모
아파치 카산드라는 아마존의 다이나모 분산 키값 저장소의 기술들을 기반으로 만들어졌습니다. 다이나모 시스템은 3개의 주요 기술로 만들어집니다.
1) 파티셔닝된 데이터셋에 coordination 요청
2) Ring기반 맴버쉽 및 failure 감지
3) 로컬 퍼시스턴스 저장소 엔진
카산드라는 처음 2개의 클러스터링 구조를 기반으로 설계되었습니다. 그리고 LSM(Log Structured Merge Tree)를 기반으로 저장소 엔진을 사용합니다.
- 일관된 해싱을 통한 데이터셋 파티셔닝 수행
- 버저닝된 데이터와 조정 가능한 consistency를 통한 멀티 마스터 데이터 복제
- 가십 프로토콜(gossip protocol)을 사용한 분산 클러스터 멤버쉽 추가 및 장애 감지
- 범용 하드웨어를 사용한 스케일 아웃
카산드라는 페타바이트 이상의 대규모 비즈니스에서도 저장소 요구사항을 충족하기 위해 이런 특징을 가지게 되었습니다. 특히, 애플리케이션이 항상 사용가능하며 짧은 지연의 읽기/쓰기 시간 그리고 페타바이트급 데이터셋의 전체 글로벌 복제를 지원합니다. 카산드라가 없었을 때 관계형 데이터베이스 시스템들의 스케일 아웃 이슈와 여러 요구사항에 대응할 수 없었기 때문에 이러한 기능을 지원하게 되었습니다.
데이터셋 파티셔닝 : Consistent Hashing(일관된 해싱)
카산드라는 해시 함수를 사용하여 시스템에 모든 데이터를 저장함으로서 수평 확장을 달성하게 되었다. 각 파티션들은 모든 물리 노드에 복제되며 랙 및 데이터 센터와 같은 장애 포인트를 기반으로 분산되어 복제된다. 각 복제본들은 각 파티션 키 별로 버전관리되고 독립적으로 처리된다. 다이나모의 논문에 나와 있는 방식과 다르게 카산드라는 더 간단한 버전의 데이터 저장을 사용하며 timestamp를 활용하여 "winning" 데이터를 정하게 됩니다. 공식적으로 카산드라에서 CQL을 사용한 로우에 대해서 쓰기가 동시에 일어날 경우 충돌하는 데이터를 해결할 수 있습니다.
토큰 링을 사용한 일관된 해싱
카산드라는 일관된 해싱이라고 불리는 특별한 형태의 해싱을 사용하여 저장소 노드에서 데이터를 분할하여 저장합니다. 단순 데이터 해싱에서는 파팃녀 키의 해시 함수를 사용하여 버킷에 키를 할당한다. 예를 들어 단순 해싱을 사용하여 데이터를 100개의 노드에 저장할 경우 모든 노드를 0과 100사이의 버킷에 할당하고 입력 파티션키를 100으로 해싱한 이후에 해당 버킷에 데이털르 저장한다. 그러나 이렇게 단순한 방법을 사용하면 노드를 추가할 경우 매핑이 무효화될 수 있습니다.
그렇기 때문에 카산드라는 모든 노드를 연속 해시 링(hash ring)상에 하나 이상의 토큰에 매핑을 하고, 파티션 키를 링(ring)을 기반으로 해싱하여 다음 링을 한 방향으로 "walking"하는 방식으로 소유권을 저장한다. 이 방식은 Chord 알고리즘과 유사합니다. 단순 데이터 해싱과 일관된 해싱의 주요 차이점은 저장소의 노드 수가 변경될 때 일관된 해싱은 키의 일부만 이동하면 된다는 것입니다.
예를 들어, 토큰 간격이 균일한 8개의 노드를 가진 클러스터와 3개의 복제 팩터가 있는 경우, 파티션 키에 해당하는 데이터의 소유 노드를 찾기 위해 해당 파티션 키를 해싱한 다음 세개의 고유한 노드를 찾을 때까지 시계 방향으로 링을 "걷기"시작합니다. 해당 키의 모든 복제본(gRF=3)인 클러스터(8노드)의 예는 다음과 같이 시각화 할 수 있습니다.

다이나모와 같은 시스템에서는 토큰 범위라고 하더라도 파티션 키의 범위가 동일한 노드 집합에 매핑되어 있는 것을 알 수 있습니다. 상기 그림에서 토큰 1을 제외하고 토큰 2를 포함한 모든 파티션 키는 노드 2,3,4에 저장됩니다.
물리 노드에 여러 토큰에 대응(vnodes)
단순한 단일 토큰 기반 일관된 해싱은 데이터를 분산시킬 물리 노드가 많을 경우 잘 작동합니다. 그러나 토큰 간격이 균일하고 물리 노두수가 적은 경우 링 균형을 유지할 수 있는 신규 노드에 대한 토큰 선택이 없기 때문에 incremental scaling이 어렵습니다. 카산드라는 토큰 범위가 고르지 않으면 request load가 고르지 않기 때문에 토큰 불균형을 피해야 합니다. 예를 들어, 이전 예제에서는 불균형을 초래하지 않고 아홉번째 토큰을 추가하는 방법은 없었습니다. 대신 기존 범위의 중간점에 8개의 토큰을 추가해야 합니다.
다이나모 논문을 살펴보면 이런 불균형 문제를 해결하기 위해 "가상 노드"의 사용하는 것을 고려해라고 적혀 있습니다. 가상 노드는 토큰 링의 여러 토큰을 각 물리적 노드에 할당하여 문제를 해결하는 방법입니다. 단일 물리 노드가 링에서 여러 위치에 추가 가능하도록 허용함으로써 작은 클러스터를 더 크게 운영하는 것 처럼 설정할 수 있습니다. 단일 물리 노드를 추가하더라도 더 많은 인점 노드(링 상에서)에서 데이터를 가져오는 것처럼 만들 수 있습니다.
카산드라는 이런 개념을 다루기 위해 몇가지 신규 개념을 도입했습니다.
- 토큰 : 다이나모 스타일의 해시 링 단일 위치
- 엔드포인트 : 네트워크의 단일 물리적 IP와 포트
- 호스트 ID : 일반적인 gEndpoint하나만 존재하지만, 여기서는 하나 이상의 gToken를 포함하는 단일 물리 노드에 대한 고유 식별자입니다.
- 가상 노드(vnode) : 동일한 물리 노드(gHost ID)가 소유한 해시 링의 gToken
엔드포인트의 토큰 할당은 카산드라가 어떤 링 위치가 어느 물리적 엔드포인트에 할당되는지 추적하는 토큰 맵을 생성합니다. 예를 들어, 다음 그림에서 모든 노드에 각 2개의 토큰을 할당하여 4개의 물리 노드만 사용하는 8개 노드 클러스터로 구성할 수 있습니다.
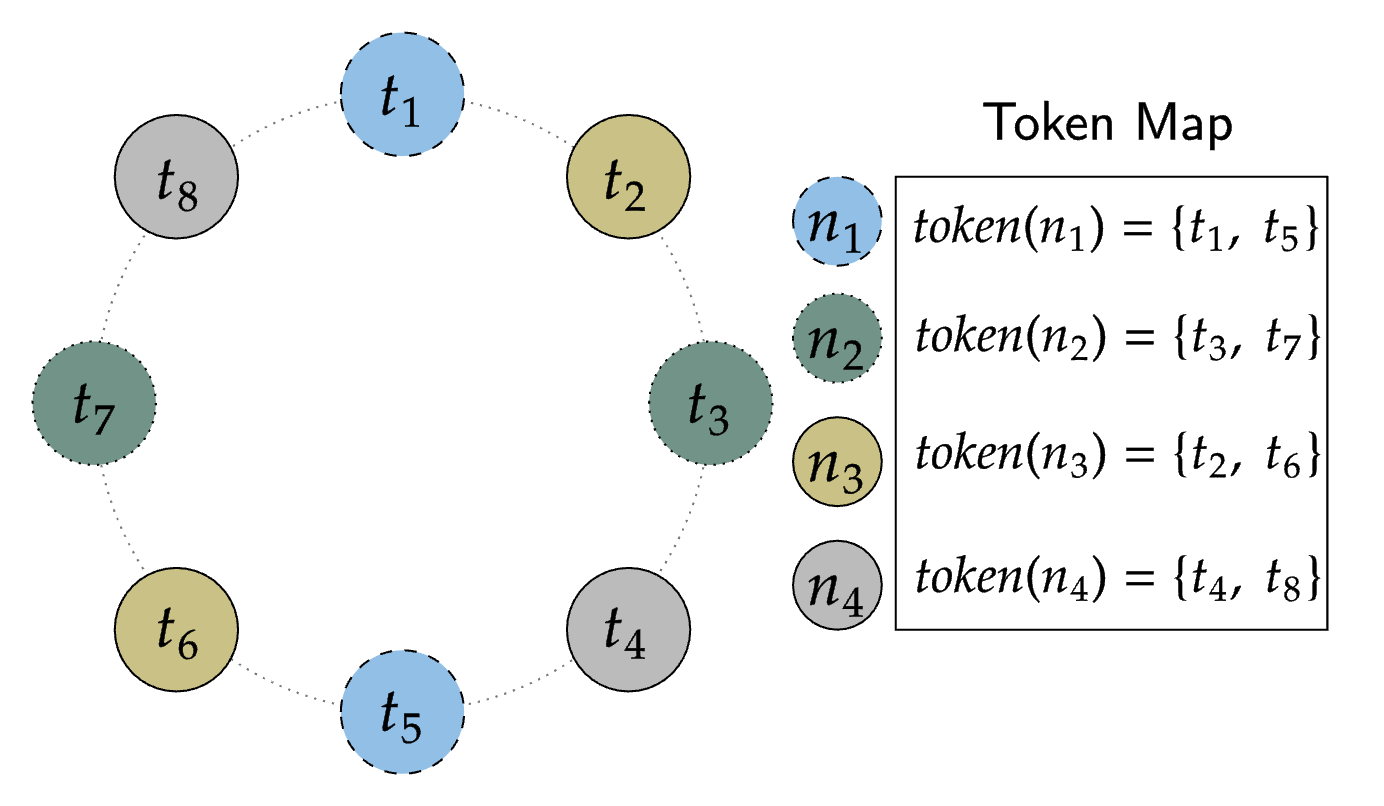
물리 노드당 여러 토큰을 활용하면 다음과 같은 이점이 있습니다.
- 새 노드가 추가되면 링의 다른 노드로부터 대략적으로 동일한 양의 데이터를 수신하여 클러스터 전체에 걸쳐 데이터가 균등하게 분배됩니다.
- 노드가 탈락되면 다른 링 멤버들과 거의 동일하게 데이터가 사라지고, 다시 클러스터 전체에 걸쳐 데이터가 균등하게 분배된다.
- 노드를 사용할 수 없게되면 쿼리 로드(특히 토큰 인식 쿼리 로드)가 많은 노드에 고르게 분산됩니다.
반면, 단점은 다음과 같습니다.
- 모든 토큰은 최대 2*(RF-1)개의 추가 이웃이 생깁니다. 즉, 토큰의 일부에 대해서 가용성을 잃을 수 있는 실패 가능성이 많습니다. 토큰이 많을 수록 다운타임 확률이 높아집니다.
- 클러스터 전체의 유지보수 작업이 느려질 수 있습니다. 예를 들어, 노드 당 토큰 수가 증가하면 클러스터에서 수행해야 하는 개별 복구 작업 수도 증가합니다.
- 여러 토큰 범위에 걸쳐있는 작업이 성능에 영향을 미칠 수 있습니다.
카산드라 2.x에서 사용할 수 있는 유일한 토큰 할당 알고리즘은 임의 토큰을 선택하는 것이였습니다. 이 때는 토큰 수를 256개로 매우 높게 유지해야만 했습니다. 이는 많은 물리 엔드포인트가 함께 결합하는 영향으로 인해 다운타임이 발생할 가능성을 증가시켰습니다. 결과적으로 3.x 버전 이후에서는 결정론적 토큰 할당자(deterministic token allocator)가 추가되어 물리 노드당 훨씬 적은 수의 토큰을 지정함으로서 링이 최적으로 균형을 이루도록 설정할 수 있게 되었습니다.
멀티 마스터 복제: 버저닝된 데이터와 일관성 튜닝
카산드라는 높은 가용성과 내구성을 가지기 위해 모든 데이터를 파티션 단위로 클러스터 전체 노드에 복제하여 저장합니다. 데이터가 변경되면 코디네이터가 파티션 키를 해싱하여 데이터가 속한 토큰의 범위를 결정하고나서 복제 전략에 따라 해당 데이터를 복제본에 복제합니다.
모든 복제 전략은 복제 팩터(Replication Factor) 개념을 지니고 있으며 파티션의 복사본 데이터가 몇개나 존재해야 하는지를 나타냅니다. 예를 들어 RF=3 키스페이스를 사용하면 데이터가 3개의 복제 데이터가 존재하는 것입니다. 복제본은 항상 서로 다른 물리 노드에 분리되어 자장되며, 필요한 경우 가상 노드는 건너뛰어 수행됩니다. 복제 전략은 카산드라 클러스터가 전제 책과 노드 데이터 센터 장애에 견딜 수 있도록 관련 기능을 지정할 수도 있습니다.
복제 전략
카산드라에서는 어떤 물리 노드들이 제공되었을 때 어떻게 복제를 진행할 것인지 결전하도록 복제 전략을 지정할 수 있습니다. 모든 키스페이스는 데이터를 저장하기 위해 고유한 복제 전략을 지정할 수 있습니다. 상용 환경에서는 모두 NetworkTopologyStrategy를 사용해야 하지만 테스트를 위해서는 SimplStrategy 복제 전략을 사용해도 됩니다.
- NetworkTopologyStrategy
NetworkTopologyStrategy를 사용하려면 클러스터의 각 데이터 센터에 대해 지정된 복제 팩터가 필요합니다. 클러스터에서 단일 데이터 센터만 사용한 경우에도 나중에 새로운 물리 또는 가상 데이터 센터를 추가할 수 있도록 SimpleStrategy 보다는 NetworkTopologyStrategy를 선택하는 것이 좋습니다.
복제 팩터를 데이터 센터별로 개별적으로 지정할 수 있을 뿐만 아니라 NetworkTopologyStrategy는 데이터 센터 내의 복제본을 스니치(Snitch)에서 지정한 서로 다른 랙에 저장을 시도합니다. 랙 수가 데이터 센터의 복제 팩터보다 크거나 같으면 각 복제본을 서로 다른 랙에 저장할 수 있습니다. 그렇지 않으면 각 랙에는 하나 이상의 복제본이 저장될 수 있고 하나의 랙에는 2개 이상의 복제본이 저장될 수도 있습니다. 이런 랙 동작은 이슈가 발생할 가능성이 있습니다. 예를 들어, 각 랙에 짝수 개수의 노드가 엇는 경우 가장 작은 랙의 노드의 로드는 훨씬 더 높을 수 있습니다. 이런 이유로 많은 운영자는 단일 가용성 영역 또는 유사 장애 도메인의 모든 노드를 단일 랙으로 구성하는게 일반적입니다.
- SimpleStrategy
SimpleStrategy를 사용하면 단일 정수를 replication factor를 정의할 수 있습니다. 각 로우를 복제한 데이터를 가져야하는 노드 개수를 결정합니다. 예를 들어 RF=3이면 서로 다른 세 개의 노드가 각 로우의 복사본을 저장해야 한다는 뜻입니다.
SimpleStrategy는 구성된 데이터 센터 또는 랙을 무시하고 모든 노드를 동일하게 가정하고 처리합니다. 토큰 범위의 복제 데이터를 결정하기 위해, 카산드라는 관련 토큰 범위(token range of interest)부터 시작하여 링의 토큰을 반복합니다. 각 토큰에 대해 소유 노드가 복제본 집합에 추가되었는지 확인하고, 추가되지 않은 경우 집합에 추가합니다. 이 프로세스는 RF 개별노드가 복제본 집합에 추가될때까지 계속됩니다.
순간적 복제(Transient Replication)
순간적 복제는 카산드라 4.0의 실험적인 기능입니다.
https://cassandra.apache.org/doc/latest/cassandra/architecture/dynamo.html#transient-replication
Dynamo | Apache Cassandra Documentation
Cassandra achieves horizontal scalability by partitioning all data stored in the system using a hash function. Each partition is replicated to multiple physical nodes, often across failure domains such as racks and even datacenters. As every replica can in
cassandra.apache.org
데이터 버저닝
카산드라는 데이터의 궁극적인 일관성을 보장하기 위해 변경된 데이터의 타임스탬프를 기준으로 버전 관리를 사용합니다. 특히 시스템에 추가되는 모든 변경데이터는 클라이언트의 시계에서 제공되거나 클라이언트에서 제공되지 않은 경우에는 코디네이터 노드의 시계의 타임스태프를 기반으로 동작합니다. 쓰기가 가장 마지막에 된 데이터를 기준으로 업데이트가 수행됩니다. 카산드라의 정확성은 이런 시계들에 달려있기 때문에 NTP와 같은 적절한 시간 동기화 과정이 실행 중인지 확인해야 합니다.
카산드라는 CQL 파티션 내에 있는 모든 로우의 모든 컬럼에 별도의 변경 타임스탬프를 적용합니다. 컬럼은 키 별로 고유하도록 보장되고 로우의 각 컬럼은 last-write-wins 에 따라 동시 데이터 변경에 대응하여 해소합니다. 즉, 파티션 내의 다른 키에 대한 업데이트는 충돌 없이 해결될 수 있습니다. 또한 map, set와 같은 CQL 컬렉션 유형에서도 동일한 타임스탬프 매커니즘을 사용하여 해소합니다.
복제 동기화
카산드라의 복제 데이터들에 대해 독립적으로 변경 데이터를 받을 수 있기 때문에 특정 복제 데이터는 다른 복제 데이터보다 더 신규 데이터를 가질 수 있게 됩니다. 카산드라는 읽기 경로 레플리카 복구인 <read-repair>와 쓰기 경로의 암시 핸드 오프인 <hint>를 비롯하여 많은 기술을 지니고 있습니다.
그런 이런 기술은 동기화를 위한 최선의 노력 뿐이며 궁극적인 일관성을 보장하기 위해 카산드라에서는 Merkle트리라고 불리는 데이터셋에 대해 계층적 해시 트리를 계산한 다음 복제 데이터들을 비교하여 일치하지 않는 데이터를 식별하여 <repair>를 통해 안티 엔트로피 복구를 수행합니다. 다이나모 논문의 구현체처럼 카산드라는 복제 데이터들이 전체 데이터 셋을 해시하고 Merkle 트리를 생성하고 서로 전송을 통해 일치하지 않는 범위의 데이터들을 동기화 하는 전체 복구(full repairs)를 지원합니다.
원래 다이나모 논문과 다르게 카산드라는 하위 범위 수리 및 증분 수리도 수행할 수 있습니다. 카산드라는 하위 범위 복구를 통해 데이터 범위의 일부에만 걸쳐져 있는 더많은 수의 트리를 생성하여 해시 트리 해상도를 높일 수 있습니다. 증분 수리는 카산드라가 수행한 마지막 수리 이후 변경된 파티션만 수리할 수도 있습니다.
일관성 튜닝
카산드라는 일관성 튜닝을 통해 일관성과 가용성 사이에서 어떤 균형을 가질 것인지 선택할 수 있습니다. 카산드라의 일관성 수준은 다이나모의 R+W>N 일관성 메커니즘 버전입니다. 여기서 작업자는 읽기(R)와 쓰기(W)에 참여해야 하는 노드의 수를 복제 계수(N)보다 크게 구성할 수 있습니다. 대신 카산드라에서는 복제 패터를 모르더라도 R과 W의 동작을 선택할 수 있는 공통된 일관성 수준을 선택할 수 있습니다.
아래와 같은 일관성 레벨을 설정할 수 있습니다.
- ONE : 단일 복제본만 응답 받음.
- TWO : 두 개의 복제본에 응답 받음.
- THREE : 세 개의 복제본에 응답 받음.
- QUORUM : 복제본의 과반수(n/2+1)에서 응답 받음.
- ALL : 모든 복제본에서 응답 받음.
- LOCAL_QUORUM : 로컬 데이터 센터(코디네이터가 있는 데이터 센터)에 있는 복제본의 과반수에서 응답 받음.
- EACH_QUORUM : 각 데이터 센터에 있는 복제본의 과반수에서 응답 받음.
- LOCAL_ONE : 단일 복제본에서 응답. 다중 데이터 센터 클러스터에서는 원격 데이터 센터의 복제본로 응답을 보내지 않음.
- ANY : 단일 복제본이 응답하거나 또는 코디네이터가 힌트 저장 가능. 힌트가 저장된 경우 코디네이터는 힌트를 재생하여 복제본에 변경된 데이터를 전달하려고 시도. 이 수준은 쓰기 작업에서만 허용됨.
쓰기 작업 자체는 일관성 단계에 상관없이 항상 모든 복제본으로 전송됩니다. 일관성 수준은 코디네이터가 클라이언트에 응답하기 전에 기다리는 응답 수를 제어합니다.
읽기 작업은 일반적으로 코디네이터의 일관성 수준을 만족시킨 충분한 복제본에 대해서만 읽기 명령이 내려집니다. 단, 원본 복제본이 지정된 시간내에 응답하지 않으면 추가된 복제본에 대해 중복 읽기가 발생할 수 있습니다.
일관성 단계 고르기
일반적으로 복제 계수와 일관성 단계를 고르는 것은 함께 고려되어야 합니다. 복제 계수에 따라 일관성 단계의 영향이 달라지기 때문입니다. 이는 일반적으로 다이나모의 W+R>RF와 동일한 용어로 표현됩니다. 여기서 쓰이는 W는 쓰기의 일관성, R은 읽기의 일관성, RF는 복제 계수입니다. 예를 들어 RF=3인 경우 QUORUM으로 설정하면 최소한 2/3 복제본의 응답이 필요하다. QUORUM이 쓰기 및 읽기에 모두 사용될 경우, 하나 이상의 복제본이 쓰기 및 읽기 요청에 모두 참여하도록 보장되므로 읽기와 쓰기 모두 영향을 받습니다.
다중 데이터 센터 환경에서 LOCAL_QUORUM을 사용하면 더 유용한 보장을 사용할 수 있습니다. 동일 데이터 센터 내에서 최신 쓰기가 확인되도록 보장합니다. 단일 데이터 센터에 클라이언트의 쓰기와 읽기를 수행한다면 이 설정이 충분할 수 있습니다.
만약 강력한 일관성이 필요하지 않다면 LOCAL_ONE이나 ONE과 같은 낮은 일관성 수준을 사용하여 처리량, 지연 시간 및 가용성을 향상시킬 수 있습니다. 여러 데이터 센터에 걸친 복제에서 일반적으로 LOCAL_ONE 설정은 가용성이 1보다 낮지만, 빠른 속도를 가지게 된다. 실제로 데이터 센터에서 단일 데이터 복제본을 사용할 경우에는 ONE으로 설정하는 것이 좋습니다.
분산 클러스터 맴버쉽과 장애 감지
복제 프로토콜 및 데이터셋의 파티셔닝은 활성/비활성 노드가 있는 클러스터에서 쓰기와 읽기 작업을 최적으로 라우팅하도록 수행할 때 사용됩니다. 카산드라에서 노드 활성 정보는 가십 프로토콜을 기반으로 고장 감지 매커니즘을 수행합니다.
가쉽(gossip)
가쉽은 카산드라가 엔드포인트 멤버쉽과 내부 노드 네트워크 프로토콜 버전과 같은 기본 클러스터의 부트스트래핑 정보를 전파하는 방법입니다. 카산드라의 가쉽 시스템에서 노드들은 노드 자신 뿐만 아니라 그들이 알고 있는 다른 노드들에 대해서도 상태 정보를 교환합니다. 이 정보는 튜플(세대, 버전)의 벡터 클럭으로 버전화되어 있으며, 여기서 타임스탬프의 버전이 매초마다 증가하는 논리 클럭으로 지정됩니다. 이런 논리 시계(클럭)은 카산드라 가쉽이 가쉽 메시지로 제시된 논리 시계를 검사하는 것만으로도 이전 버전의 클러스터 상태를 무시할 수 있게 됩니다.
각 클러스터의 모든 노드는 가쉽 작업을 독립적이고 주깆거으로 실행합니다. 클러스터의 모든 노드는 각 초마다 다음 기능을 수행합니다.
1) 로컬 노드의 하트비트 상태(버전)을 업데이트하고 클러스터 가쉽 엔드포인트 상태에 대한 로컬 뷰를 생성합니다.
2) 가쉽 엔드포인트의 상태를 교환할 클러스터의 다른 노드를 임의로 선택합니다.
3) 연결할 수 없는 노드 또는 연결할 수 있는 노드가 있는 경우 가쉽을 시도합니다.
4) 2단계에서 수행할 수 없는 경우 시드 노드로 가쉽을 수행합니다.
운영자가 카산드라 클러스터를 처음 부트스트랩할 때 cassandra.yaml에서 특정 노드를 시드 노드로 지정합니다. 모든 노드는 시드 노드가 될 수 있으며 시드 노드와 비 시드 노드의 유일한 차이점은 시드 노드가 다른 시드 노드를 보지 않고 링으로 부트스트랩할 수 있다는 점입니다. 또한 클러스터가 부트스트랩되면 위 4단계로 인해 시드 노드가 가쉽의 핫스팟이 됩니다.
비 시드 노드가 클러스터로 부트스트랩을 하려면 하나 이상의 시드 노드에 연결할 수 있어야 하므로 일반적으로 여러 시드 노드를 포함할 수 있습니다.(일반적으로 랙 또는 데이터 센터마다 하나씩 지정). 시드 노드는 기존 서비스 검색 매커니점을 사용하여 선택하는 경우가 많습니다.
현재 가쉽 알고리즘은 메타데이터 및 스키마 버전 정보도 공유합니다. 이 정보는 데이터 이동 및 스키마 풀 스케줄을 위한 것입니다. 예를 들어 가쉽 상태에서 스키마 버전이 일치하지 않는 노드가 발견되면 다른 노드와의 스키마 동기화 작업을 예약합니다. 토큰 정보는 가쉽을 통해 전파되므로 어떤 엔드포인트가 어떤 데이터를 소유하는지 지정하는 녿의 제어 영역이기도 합니다.
링 맴버쉽과 장애 감지
가쉽 알고리즘은 링 멤버쉽의 기초를 형성하지만, 실패 감지는 궁극적으로 노드가 UP/DOWN인지에 따라 달라집니다. 카산드라의 모든 노드는 여러 종류의 Phi Accural Failure Detactor를 사용하는데, 여기서 모든 노드는 피어 노드를 사용할 수 있는지 여부에 대한 독립적인 결정을 지속적으로 내립니다. 예를 들어, 특정 시간 동안 노드에서 증가하는 하트비트를 감지하지 못한다면 장애 감지기는 해당 노드에 "convict"하여 읽기 라우팅을 중지합니다. 만약 노드가 다시 하트비트를 시작하면 카산드라는 연결을 시도하고 통신 채널을 열 수 있다면 해당 노드를 사용 가능한 것으로 표시합니다.
UP/DOWN 상태는 로컬 노드의 결정이며 가쉽을 통해 전파되지는 않습니다. 하트비트 상태는 가쉽을 통해 전파되지만 실제 네트워크 채널을 통해 서로 성공적으로 메시지를 전달할 수 있기 전까지는 DOWN으로 처리합니다.
카산드라는 권한 해제 작업이나 replace_address_first_boot 옵션이 있는 새 노드 부트스트래핑을 통해 운영자의 명시적인 명령 없이는 노드를 가쉽 상태에서 제거할 수 없습니다. 이를 통해 데이터를 불필요하게 재조정하지 않고 카산드라 노드가 일시적으로 장애를 일이 킬 수 있도록 하기 위해 설계되어 있습니다. 또한 토큰 범위의 여러 복제 데이터들이 동시에 이동하는 것을 방지하여 일관성을 위반하고 데이터 손실을 초래하는 것을 방지합니다.
범용적 하드웨어에서 스케일 아웃
카산드라는 스케일 아웃을 통해 데이터의 처리량의 크기와 속도를 증가시킬 수 있습니다. 스케일 아웃은 링에 노드를 추가하는 것을 의미하며 노드를 추가할 때 마다 컴퓨팅 및 스토리지의 선형적인 개선을 얻을 수 있습니다. 이와 대조적으로 스케일 업은 기존 노드의 용량을 추가하거나 cpu, 메모리 증가를 뜻합니다.
심플 쿼리 모델
카산드라는 다이나모와 마찬가지라 SQL DRMS에 일반적인 파티션 간 트랜잭션을 제공하지 않습니다. 이는 프로그래머에게 더 간단한 읽기와 쓰기 API를 제공하며 다중 노드에 걸친 다중 파티션 트랜잭션은 구현하기 어려우며 여러 이슈가 발생할 가능성이 있습니다. 이를 제공하지 않음으로서 카산다르나 수평적으로 더 쉽게 확장할 수 있게 되었습니다.
대산 카산드라는 단일 파티션 작업을 위해 어떤 규모에서든 빠르고 일관된 대기 시간을 제공하여 전체 파티션을 검색하거나 기본 키 필터를 기반으로 파티션 하위 집합만 검색할 수 있습니다. 또한 카산드라는 경량 트랜잭션 CQL API를 통해 단일 파티션에 대해 비교와 swap 기능을 제공합니다.
레코드를 저장하기 위한 간단한 인터페이스
카산드라는 다이나모에서 약간 벗어나 "심플 키 값" 저장소보다 정교하면서도 RDMS보다는 덜 복잡한 스토리지 인터페이스를 선택했습니다. 카산드라에 데이터 파티션에 여러개의 행이 포함된 wide-column 저장소 인터페이스를 제공합니다. 각 로우에는 유연한 개별 컬럼이 포함되어 있습니다. 각 행은 파티션 키와 하나 이상의 클러스터링 키로 고유하게 식별되며 모든 로우에는 필요한 만큼 컬럼이 있을 수 있습니다.
이를 통해 기존 데이터셋 에 새로운 컬럼을 유연하게 추가할 수 있습니다. 스키마 변경에는 메타데이터 변경만 포함되며 현재 실행중인 워크로드와 동시에 실행됩니다. 따라서, 사용자의 쿼리 성능은 저하되지 않으면서도 열을 안전하게 추가할 수 있습니다.
출처 : https://cassandra.apache.org/doc/latest/cassandra/architecture/dynamo.html
Dynamo | Apache Cassandra Documentation
Cassandra achieves horizontal scalability by partitioning all data stored in the system using a hash function. Each partition is replicated to multiple physical nodes, often across failure domains such as racks and even datacenters. As every replica can in
cassandra.apache.org
'빅데이터 > cassandra' 카테고리의 다른 글
| 카산드라 TimeWindowCompactionStrategy 설명 (0) | 2022.02.07 |
|---|---|
| 카산드라와 TTL, 툼스톤 그리고 관련 동작(컴팩션) (0) | 2022.02.04 |
| 아파치 카산드라 설정 파일 및 상용 환경 셋팅 (0) | 2022.02.04 |
| 아파치 카산드라 살펴보기, 설명, 기본 개념 (0) | 2022.02.03 |
| 카산드라 TTL에 따른 데이터 삭제 정리 (0) | 2022.01.20 |
| Datastax의 Cassandra Sink Connector(JSON field) 적재 설정 (0) | 2021.12.16 |



