
https://www.confluent.io/events/kafka-summit-london-2022/modern-data-flow-data-pipelines-done-right/
Kafka Summit London 2022 Keynote | Jay Kreps, CEO, Confluent featuring Avi Perez, Wix.com
Confluent is building the foundational platform for data in motion so any organization can innovate and win in a digital-first world.
www.confluent.io
메이븐에서 카프카 자바 라이브러리의 사용율이 급격하게 올라가는 것을 볼 수 있음. 그만큼 카프카의 사용량이 엄청나게 많아지고 있다는 것을 뜻함.
카프카는 많은 기업에서 중추신경과 같은 역할을 수행하고 있음. 모든 데이터를 모으고 해당 데이터를 기반으로 연동하여 운영되고 있음.
이렇게 카프카를 사용하는 것은 크게 두가지 타입으로 나뉠수 있음. 애플리케이션과 파이프라인. 그리고 이 2개가 속한 스트리밍 플랫폼. 물론. 이 2개의 타입을 나누는 것은 정확하지 않을 수 있고 때로는 파이프라인이 애플리케이션으로 전환될 때도 있음.
문제는 여기서 이 스트리밍 데이터가 옳은 시간에 올바른 포맷으로 올바른 팀에게 적절히 가고자 할 때는 어떻게 해야하는지 고민해야 한다는 점임.

이런 문제를 해결하기 위해 다양한 솔루션들이 나왔었음. 그러나 각기 따로 운영되고 통합되지 못했음. 현재의 카프카는 필수조건이지만 카프카 자체로 모든 요구사항을 만족시키지 않다는 특징이 있음.
KAFKA IS NECESSARY BUT NOT SUFFICIENT
그리고 대부분이 배치기반 데이터 처리에 집중되고 있음. 일부는 스트리밍을 지원하지만 2022년에 새로 만들어지는 플랫폼도 배치 위주로 개발되고 있음 이런 현상은 좀 회의적임. 이와 함께 제이 크랩스는 핸리 포드의 명언을 인용했음.
핸리포드 - 만약 고객에게 무엇을 원하는지 물었다면 그들은 더 빠른 말(horse)라고 답했을 것이다
그만큼, 현재 나아가고 있는 미래는 스트림 데이터 처리임에도 불구하고 현재 배치 기반 플랫폼을 만들거나 관련 기술을 성장시키기 위해 노력하는 모습이 부정적으로 보이는 것으로 말함.

그렇기 때문에 모던 데이터 플로우를 달성하기 위해서는 카프카라는 기술적인 개념에서 넘어서서 5가지의 핵심 개념을 항상 생각해야만함.
1. 스트리밍
2. 탈중앙화
3. 선언적
4. 개발자 중심
5. 거버넌스 & 관측성
조직에 데이터가 흐르고 있는 상태에서 잘 활용하기 위한 조건이라 보면 됨.
1. 스트리밍
배치로 많은 데이터가 사용되고 있지만 앞으로 스트림 데이터가 사용될 것임에 틀림없다고 생각함. '눈을 감고 횡단보도를 걷는다고 생각할 때 5분전 교통정보를 토대로 걸을 것인가?'라는 인용과 함께 실시간 데이터만이 실제 비즈니스를 운용하는데 중심이 됨을 설명. 스트림 데이터 처리가 완벽하게 정확하지 않을 수도 있고, 리소스가 더 많이 들 수도 있고, 운영상 회의적일 수 있음. 하지만 카프카는 이런 파이프라인을 운영하는데 적합하게 구성(확장성, 내구성 등)되어 있음.

그렇기 때문에 모든 데이터를 배치 따로 스트리밍 따로 처리하지 말고 실시간으로 들어오는 데이터를 한번에 잘 처리하는 것이 더 좋은 방법이라고 생각함.
2. 탈중앙화
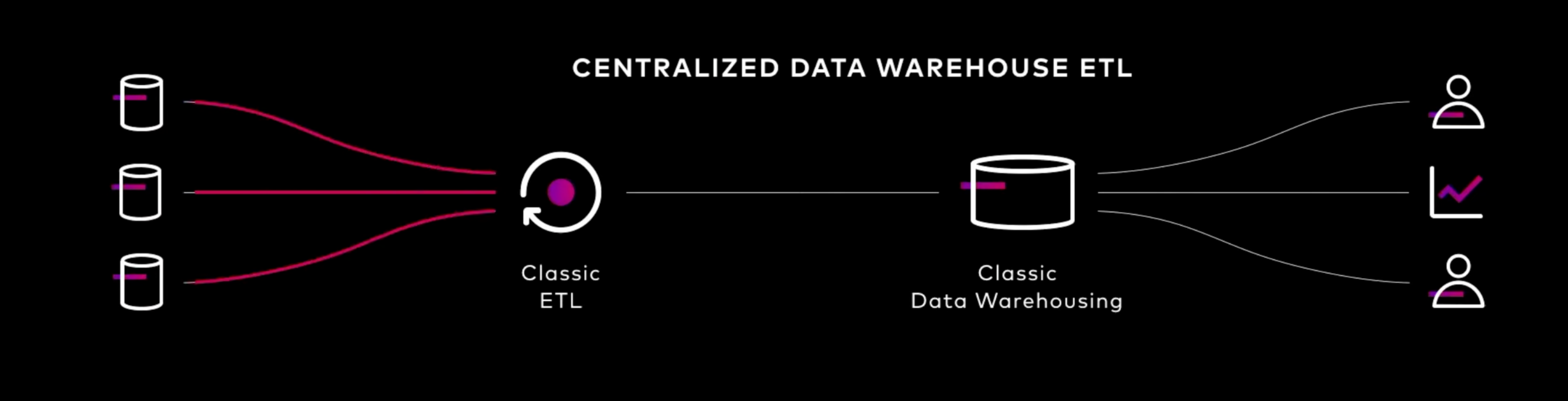
옛날 ETL은 상기 그림과 같이 단순하지만 복잡한 파이프라인을 운영하기 어려웠고 항상 중앙화된 데이터를 보아야만 했음. 실제로 우리가 비즈니스를 운영할 때는 매우 다양한 실시간/배치 데이터가 발생하고 있고 이를 상황에 따라 개별 추출하여 봐야할 경우도 있기 때문에 현대 비즈니스에는 부적합함.

그렇기 때문에 데이터를 사용하는 고객을 위한 토픽(데이터 저장)을 마들고 이를 개별적으로 가져갈 수 있도록 만드는 것이 중요.

또한, 이런 아키텍처에서는 REST+JSON 만큼이나 카프카를 스키마와 함께 사용하는 것이 중요하다고 설명함. 이 스키마를 토대로 데이터를 정확히, 잘 사용할 수 있기 때문. 다양한 요구사항을 가진 여러 고객들을 위해 토픽에 데이터를 넣고 활용할 수 있는 기회를 만들어주는 격.
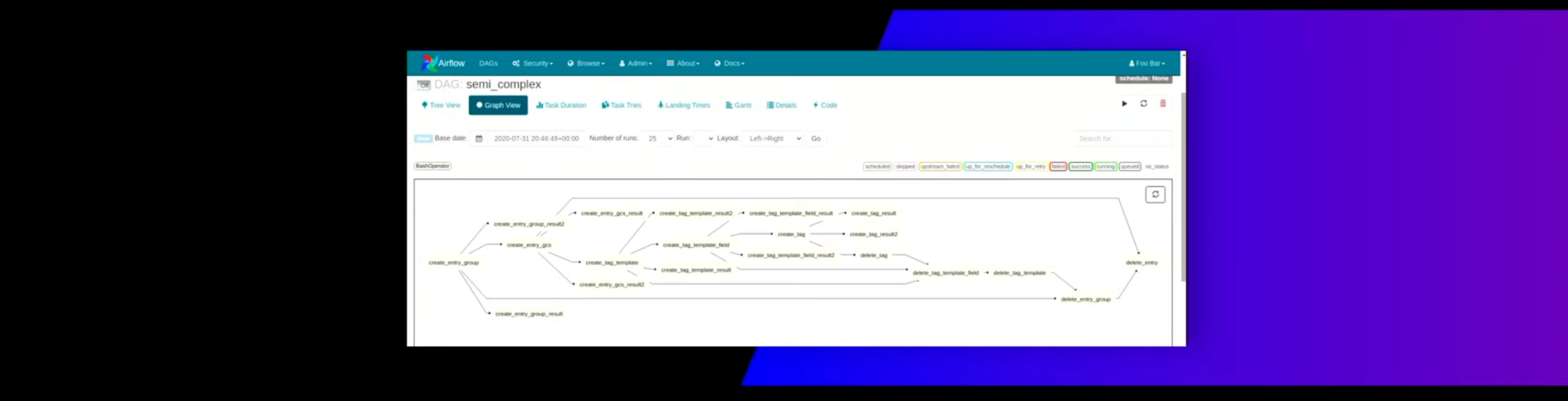
이는 일반적인 배치 프로세싱의 도구 사용 방법을 보여줌. A가 끝나면 B를 하고 C를 수행하는 이런 단계를 구성하는데 익숙함. 이런 순서 지향적 데이터 처리는 확장이 어렵기 때문에 데이터 처리 이슈를 찾기 어려움. 이를 스트림으로 구성하면 다음과 같음
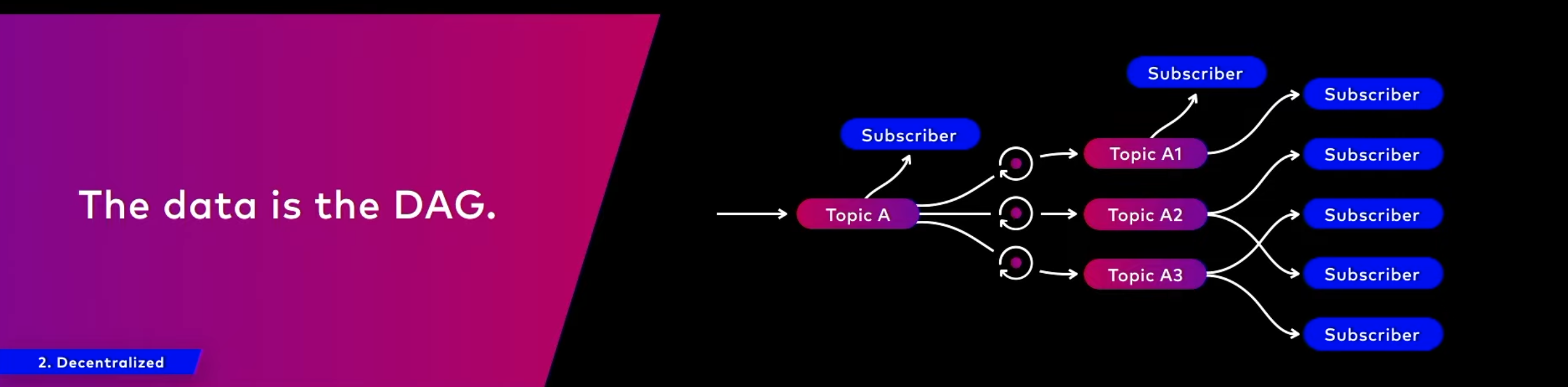
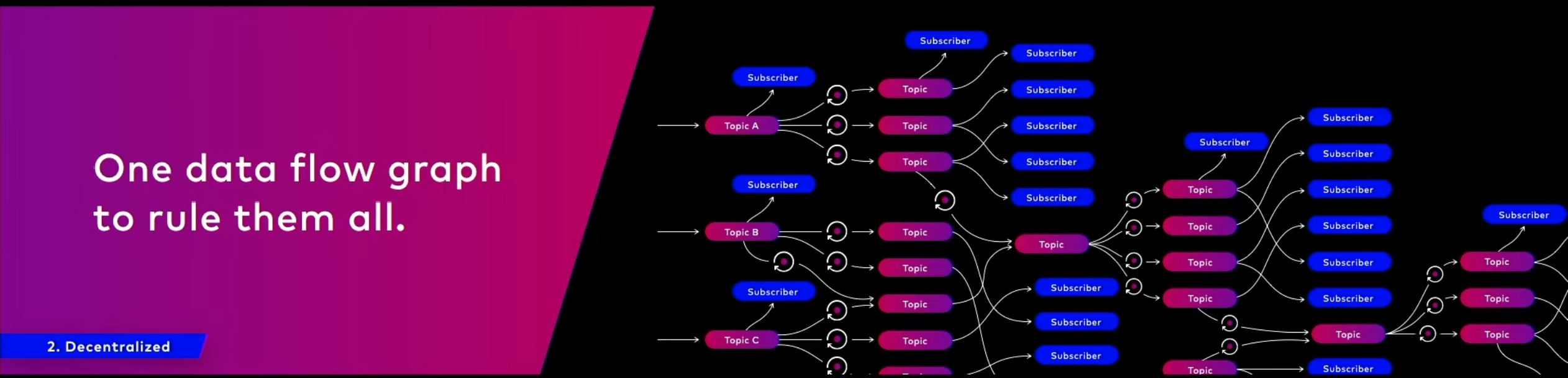
데이터는 DAG로 표현가능하기 때문에 구형의 순서지향 배치처리가 아니라 확장가능하고 여러 종류로 통합 가능한 처리를 지향.
3. 선언적
우리가 실제로 데이터를 처리할 때 어떤 것을 원하는지 정확히 적는것이 중요함. 이전에 배치성 데이터는 SQL을 잘 구성함으로서 데이터를 잘 뽑아낼 수 있었음.
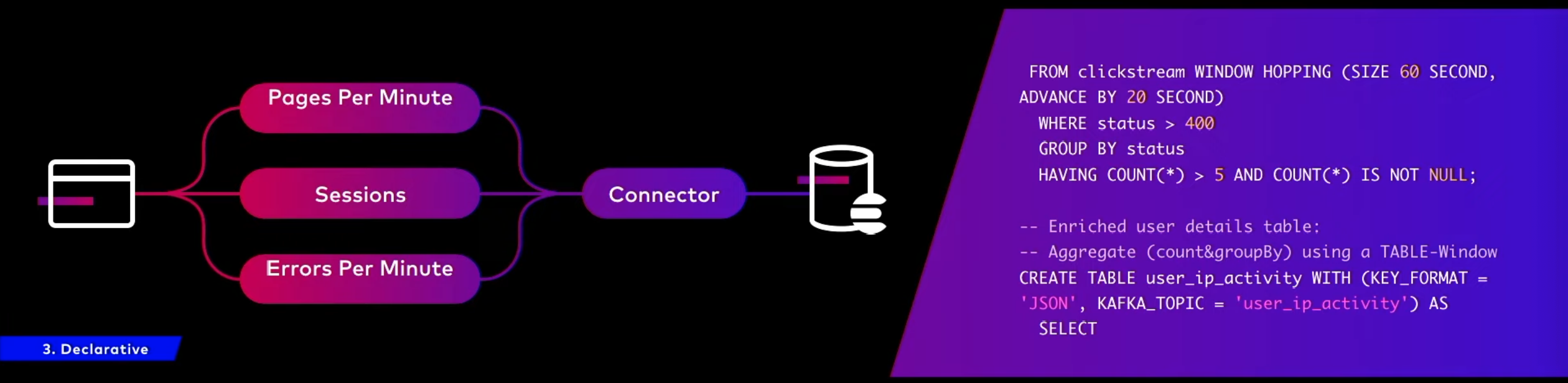
스트림도 SQL로 구성하여 뽑아 낼 수 있음. ksqlDB 광고.
4. 개발자 중심
모든 개발은 개발자 중심으로 되어야 하며 코드기반의 데이터 처리가 되어야 함. 또한 개발은 항상 발전이 되어야 하기 때문에 이를 지원하는 형태가 되어야함. 마지막으로 오픈 플랫폼을 통해 카프카 관련 파이프라인을 운영하기 위한 low level 코드와 같은 시스템이 관련 에코 시스템을 운영하기 좋아질 수 있다고 볼 수 있음.
예를 들어 새로운 커넥터가 여러 에코시스템에서 개발하고 지원하는 것을 예로 들 수 있음
5. 거버넌스 & 관측성
사실 이건 모든 데이터에서 중요함. 하지만 스트리밍에서는 이를 잘 다루어야함. 배치에서는 사실 다루기 쉬웠음. 되거나/안되거나 둘중 하나였고 실제로 안되었다면 다시 실행하면 되었기 때문임. 스트리밍은 배치와 다르게 투명하게 운영해야만 하며 이를 놓쳐서는 안됨. 또한 데이터를 사용할 때는 여러 법적인 측면도 잘 다루어야 하기 대문에 이 데이터가 어떻게 운영되고 있는지, 어떤 원천 데이터를 활용하고 있는지 파악이 되어야만함. 이를 위해 confluent에서는 Catalog, Schema, Lineage를 지원하고 있음


결론

데이터의 흐름은 모두 스트림으로 흐르고 있음. 스트림 데이터를 배치에서 변환하면 상기 이미지와 같음.
'빅데이터 > Kafka' 카테고리의 다른 글
| 기존에 생성된 compact topic의 cleanup.policy를 변경하는 방법 (1) | 2023.06.30 |
|---|---|
| Compacted topic에 null key 레코드를 전송하면? (1) | 2023.06.30 |
| 아파치 카프카 Exactly-once 처리의 진실과 거짓 (2) | 2023.06.20 |
| 아파치 카프카 브로커 설정에서 listener와 advertised.isteners의 차이? (1) | 2023.03.26 |
| windows의 WSL환경에서 아파치 카프카 설치, 실행하는 방법 (0) | 2023.02.24 |
| 커넥트 REST API 확장 플러그인 : Connect Rest Extension Plugin (0) | 2022.10.04 |



