
Telegraf와 fluentd는 아주 유사해보인다.
둘다 configuration파일 기반으로 작동하며 plugin을 통해 개발자가 custom하게 만든 input, filter, output 플러그인들을 사용하여 데이터를 처리, 전송 가능하다.
이 둘은 어떤 차이가 있는 것일까?
Fluentd
Star count(9/16) : 8,295
Github url : https://github.com/fluent/fluentd
Fluentd는 C와 루비로 작성된 로그 수집기(log aggregator)의 한 종류이다. 여러 데이터 소스에서 데이터를 수집해 오는 부분에 있어 컴포넌트로서의 역할을 한다. fluentd의 아키텍쳐 단순성과 안정성에 초점을 두고 사용된다.
Fluentd의 내부구조
- Input : 로그를 수집하는 플러그인
- Parser : 정규식 혹은 다양한 포멧의 데이터를 fluentd에서 처리할 수 있도록 파싱
- Filter : 필터링, 데이터 필드 추가/삭제/마스킹 등의 역할
- Output : 특정 데이터 저장소 솔루션에 데이터 저장하도록 설정(mongodb, s3 등)
- Formatter : Output에 저장하기 위한 포멧을 지정
- Buffer : 일정 Buffer을 통해 Throttling적용가능
Fluentd 설정
<system>
<counter_server>
scope server1
bind 127.0.0.1
port 24321
path tmp/back
</counter_server>
</system>
<source>
@type dummy
tag "test.data"
auto_increment_key number
</source>
<match>
@type stdout
</match>
Telegraf
Star count(9/16) : 7,356
Github url : https://github.com/influxdata/telegraf
Telegraf는 go로 작성된 플러그인 기반 모니터링 및 지표 수집 에이전트이다. 여러 플러그인기반으로 동작하며 별도의 의존성없이 바이너리만으로 모든 시스템에 배포 및 실행이 가능하다. 표준 StatsD 프로토콜을 지원하기 때문에 직접 개발한 애플리케이션에서도 지표를 수집할 수 있다.
Telegraf의 내부구조
- Input : 시스템, 서비스, 혹은 제 3의 api로 부터 데이터 수집
- Processor : 가져온 데이터를 변형, 필터링 등
- Aggregator : mean, min, max 등 계산
- Output : 특정 데이터 저장소에 데이터 저장
Telegraf 설정
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
debug = false
quiet = false
hostname = ""
omit_hostname = false
[[outputs.elasticsearch]]
urls = [ "http://1.123.123.123:9200" ]
timeout = "60s"
enable_sniffer = false
health_check_interval = "10s"
index_name = "my-computer-metric-%Y.%m.%d" # required.
[[inputs.diskio]]
[[inputs.kernel]]
[[inputs.mem]]
[[inputs.processes]]
[[inputs.swap]]
[[inputs.system]]
[[inputs.net]]
[[inputs.netstat]]
[[inputs.linux_sysctl_fs]]
Interest over time(year)
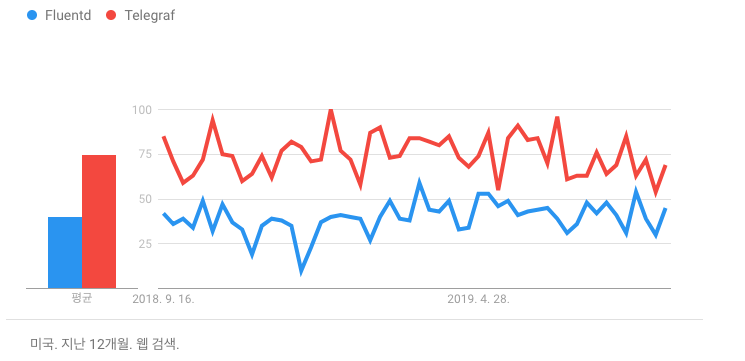
Telegraf vs Fluentd
Fluentd는 여러 데이터 소스(파일, RDBMS, NoSQL 등)을 통해 가져온 데이터를 처리하는 것에 특화되어 있다. 반면 Telegraf는 plugin기반의 서버에이전트로서 metric을 수집, 리포팅하는 역할을 수행한다. 아주 낮은 리소스를 사용하며 Metric을 수집하는데 특화되어 있다. 그래서 Fluentd는 Log Management 카테고리 그리고 Telegraf는 Monitoring tool 카테고리로 나누는 것이 적합하다고 볼 수 있다.
그러나 두 에이전트 모두 plugin이 고도화되면서 fluentd는 시스템메트릭을 수집할 수 있고, telegraf는 database기반의 데이터 로그들도 수집할 수 있으므로 두개의 구분점이 모호하게 되었다.
Fluentd의 공식홈페이지에 아래와 같은 그림이 적절한 아키텍쳐를 설명한다고 볼 수 있다.
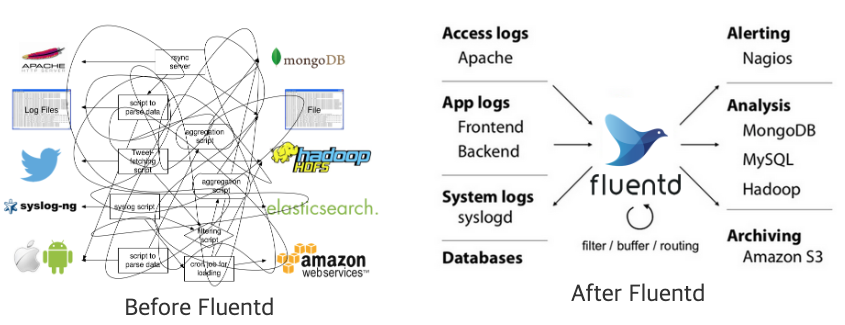
각종 script와 consumer로 섞여있던 데이터들을 fluentd로 나누어 저장하는 역할을 하는 것이다.(플러그인 기반으로)
Telegraf도 유사한데, Telegraf를 통해 log를 collect하고 metric이나 이벤트를 저장소에 저장하는 것이 fluentd의 아키텍쳐와 비슷하게 보인다.
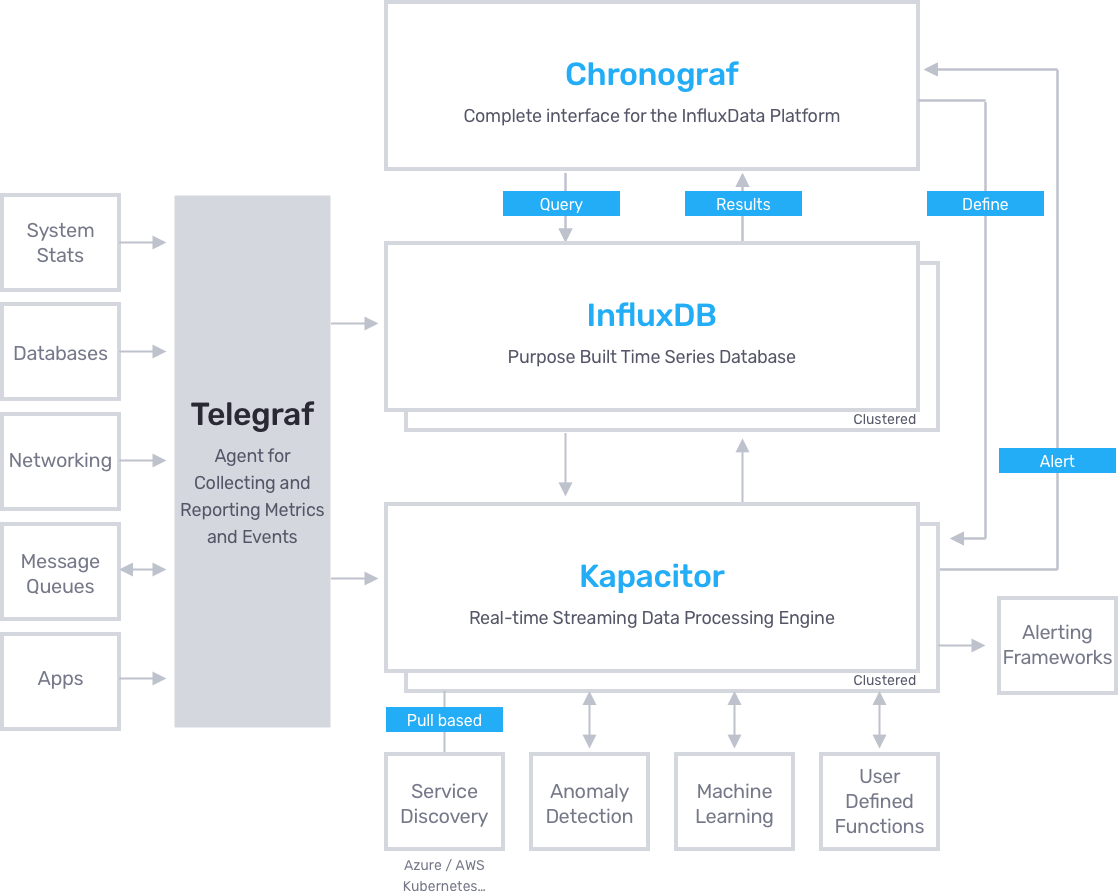
참고자료
'빅데이터' 카테고리의 다른 글
| 데이터파이프라인이란 무엇인가? (0) | 2019.10.07 |
|---|---|
| AWS에서 공개한 Data validation library 소개 - Deequ (0) | 2019.09.27 |
| Fluentd로 데이터파이프라인 구축하기 kafka→kafka→s3 (1) | 2019.09.17 |
| (번역)Netflix에서 데이터를 통해 유연하고, 안전한 클라우드 인프라로 활용하는 방법 (253) | 2019.03.22 |
| [Stream Process as a Platform] Netflix의 실시간 스트림 처리 플랫폼 Keystone 소개 (251) | 2019.01.10 |
| 모든 것을 측정하는 방법 - Bigdata시대에 부족한 data로 예측하기 (262) | 2018.12.16 |



