Fluentd개요
fluentd는 대용량 데이터처리에 있어 input/output plugin들을 사용해서 파이프라인을 생성할 수 있다. 이 파이프라인은 데이터처리에 적합한데 다양한 플러그인을 폭넓게 개발할수 있을 뿐만아니라 제공되고 있다. fluentd는 다른 fluentd에 전달도 가능한데, 이를 통해 fluentd의 트래픽을 조정하거나 라우팅할 수도 있다. 아키텍쳐 단순성과 안정성으로 인해 많은 IT기업들에서 사용된다.
파이프라인 아키텍쳐 구상 및 준비
앞서 말했듯이 강력한 input/output 플러그인 기능을 가지고 있는데, 실제로 어떤 configuration으로 사용 가능할지 알아보기 위해 아래와 같은 아키텍쳐를 구현해보기로 하였다.
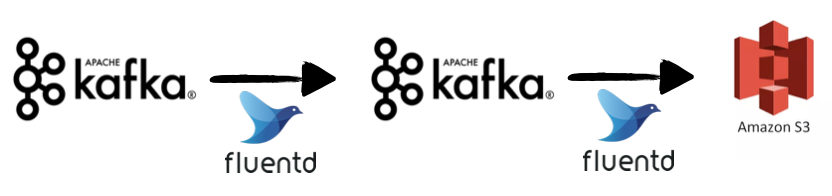
상기 아키텍쳐에서 파이프라인은 2개로 나뉘어져 있다.
1) kafka to kafka
2) kafka to s3
위 파이프라인을 구성하기 위해 사용한 플러그인은 아래와 같다.
- fluent-plugin-kafka : https://github.com/fluent/fluent-plugin-kafka
- fluent-plugin-s3 : https://github.com/fluent/fluent-plugin-s3
각 플러그인을 설치하기 위해서는 아래와 같이 command한다.(이미 fluentd가 설치되어있음을 가정)
$ fluent-gem install fluent-plugin-kafka
$ fluent-gem install fluent-plugin-s3각 파이프라인별 설정
1) kakfa에서 kafka로 데이터 전송하기
특정 kafka topic에서 또 다른 kafka topic으로 데이터를 전송하기 위해서 아래와 같은 configuration을 사용했다.
<source>
@type kafka
brokers 123.123.123.71:9092,123.123.123.72:9092,123.123.123.73:9092
topics fluentd-test-json
format json
</source>
<match fluentd-test-json>
@type kafka2
brokers 11.11.11.71:9092,11.11.11.72:909211.11.11.73:9092
default_topic fluentd-test
<format>
@type json
</format>
<buffer fluentd-test>
@type memory
flush_interval 3s
</buffer>
</match>123.123.123으로 시작하는 kafka의 fluentd-test-json 이라는 topic(json 형태)를 source로 한다. 해당 데이터를 최종 목적지로 11.11.11로 시작하는 kafka의 fluentd-test로 보내는 역할을 한다.
source에서 사용한 kafka의 topic format은 json인데, 현재 지원하는 format은 text, json, ltsv, msgpack이다. 추가로 ruby-kafka에 대응되는 여러 옵션들을 사용 할 수 있다. (ruby-kafka의 consumer options)
match의 kafka2에서는 producer역할을 한다고 볼수 있는데, 이 또한 ruby-kafka에 대응되는 producer option들을 사용할 수 있지만, 따로 설정없이 기본값을 사용하도록 하였다. 다만 buffer을 memory에 담도록하고 flush_interval을 3초로 설정하여 buffer을 두었다. 버퍼기능을 통해 네트워크장애등으로 인해 데이터가 output에 정상적으로 도달하지 못했을때 어떻게 수행할지에 대해 선언가능하다. 이 buffer관련 옵션은 buffer 설명 링크에서 확인할 수 있다. 크게 두가지 type이 있는데 파일 혹은 메모리 방식으로 나뉘어지며, 상기 테스트용 파이프라인에서는 크게 신경쓸 옵션이 아니라서 chunk_limit_size, total_limit_size 등의 설정은 하지 않았다.
2) kakfa에서 s3로 데이터 전송하기
특정 kafka topic에서 s3로 데이터를 저장하는 기능을 아래와 같이 configration설정했다.
<source>
@type kafka
brokers 11.11.11.71:9092,11.11.11:9092,11.11.11.73:9092
topics fluentd-test
format json
</source>
<match fluentd-test>
@type s3
aws_key_id A----------
aws_sec_key 3------------------------
s3_bucket fluentd-di-test
s3_region ap-northeast-2
path logs/
<buffer tag,time>
@type file
path /Users/a1003855/Documents/fluentd-test/s3
timekey 2 # 1 hour partition
timekey_wait 1s
timekey_use_utc true # use utc
chunk_limit_size 10m
</buffer>
</match>
11.11.11로 시작하는 kafka의 fluentd-test topic의 json 데이터들을 s3에 저장하는 파이프라인이다.
source의 kafka에 대한 역할은 위에 kafka에서 kafka로 전송할때와 같이 consumer로서의 역할을 수행한다.
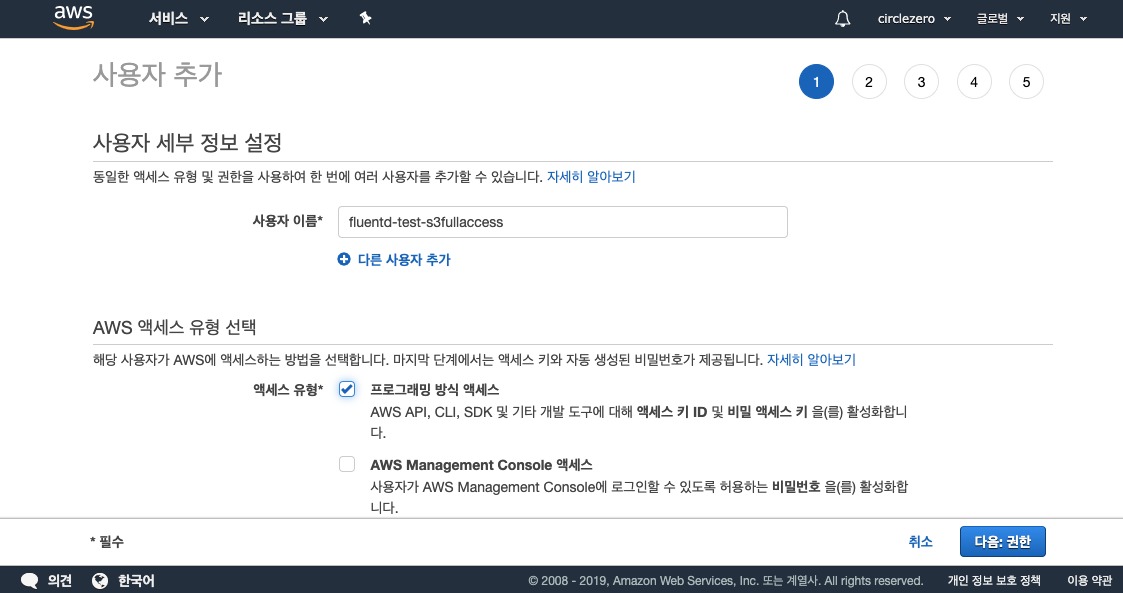
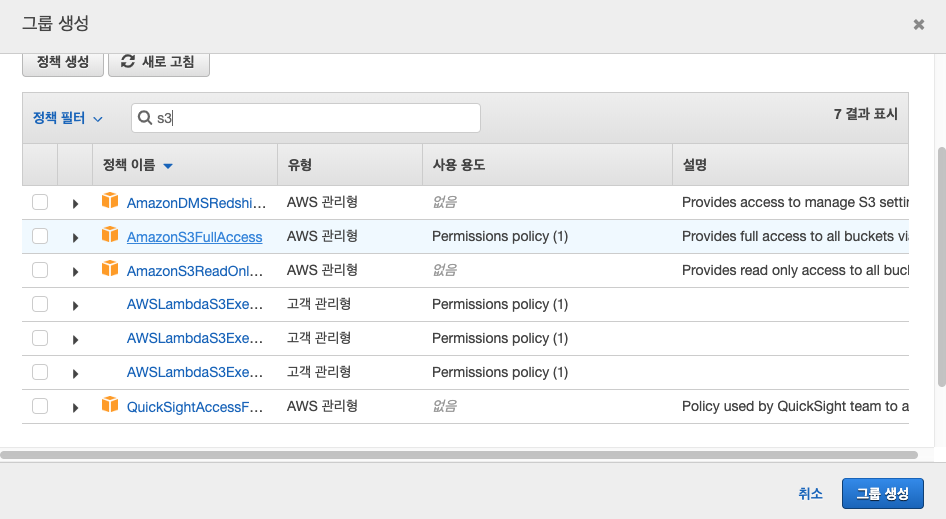
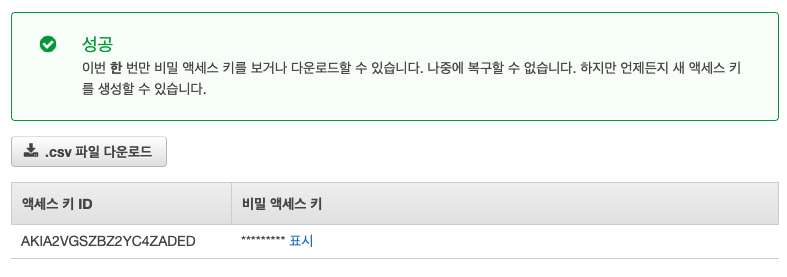
match의 s3에서는 s3저장역할을 실질적으로 수행하는 녀석인데, s3의 bucket, region, aws key, aws sec를 기본적으로 설정해야한다. aws key, sec을 s3에 저장하는 용도로 사용하기 위해 IAM에서 s3FullAmazonS3FullAccess group으로 user를 생성하여 key, sec을 발급받았다.
파이프라인 실행 및 데이터 입력하기
위에서 설정하고 저장한 configuration file을 기반으로 아래와 같이 2개의 fluentd를 실행시킨다.
$ fluentd -c kafka-kakfa.conf
$ fluentd -c kafka-s3.conf파이프라인이 정상적으로 작동하는지 확인하기 위해 가장 처음 출발 토픽인 fluentd-test-json에 json을 입력해본다. json입력은 kafka console producer로 간편하게 입력할 수 있다.
$ /usr/local/Cellar/kafka/2.0.0/bin/kafka-console-producer \
--broker-list 123.123.123.71:9092,123.123.123.72:9092,123.123.123.73:9092 \
--topic fluentd-test-json
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>{"name":"wonyoung","salary":56000,"region":"seoul"}
>파이프라인 결과 확인하기
각 파이프라인에 위에서 입력한 데이터가 kafka를 지나 s3까지 정상적으로 적재되었는지 확인하기 위해서 kafka console consumer을 통해 확인해보자.
$ /usr/local/Cellar/kafka/2.0.0/bin/kafka-console-consumer \
--bootstrap-server 123.123.123.71:9092,123.123.123.72:9092,123.123.123.73:9092 \
--topic fluentd-test-json
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}$ /usr/local/Cellar/kafka/2.0.0/bin/kafka-console-consumer \
--bootstrap-server 11.11.11.71:9092,11.11.11.72:909211.11.11.73:9092 \
--topic fluentd-test
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}
{"name":"wonyoung","salary":56000,"region":"seoul"}위와 같이 정상적으로 들어오는 모습을 확인할 수 있다. 두번째 kafka topic에 들어오는 속도가 약간 느린것 같은데 아마 producer설정이나 buffer로 인한 약간의 delay로 보인다. 이 부분은 추후 확인해볼것이다. 두번째 kafka topic인 fluentd-test까지 도착한것을 확인했으니 이제 s3에 정상적재되었는지 확인해보자.
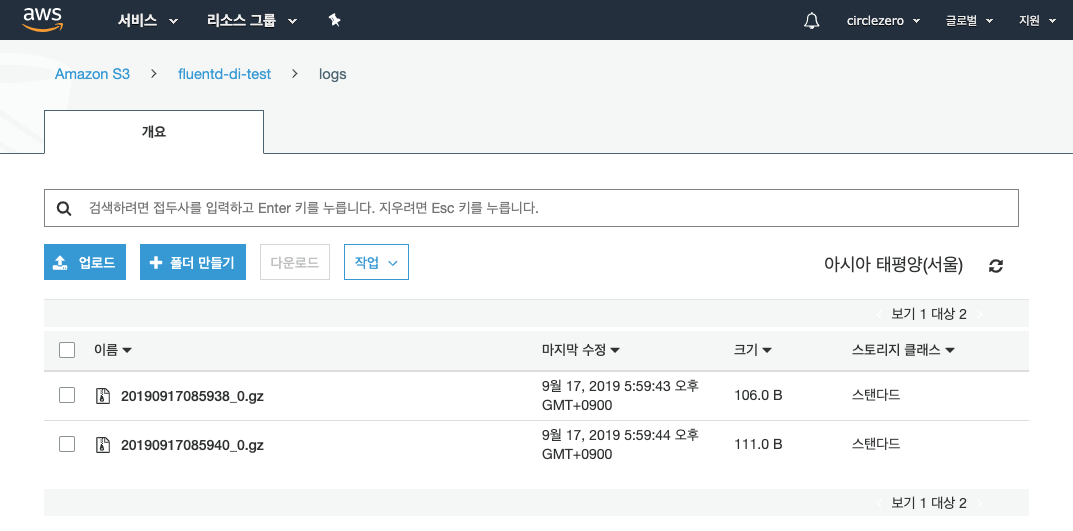
gzip형태로 s3에 파일이 잘 적재된 것을 확인할 수 있다. gzip파일에 저장된 내용을 local에 다운받아 확인하면 아래와 같이 적재되어 있음을 확인할 수 있었다.
2019-09-17T17:59:38+09:00 fluentd-test {"name":"wonyoung","salary":56000,"region":"seoul"}
2019-09-17T17:59:41+09:00 fluentd-test {"name":"wonyoung","salary":56000,"region":"seoul"}
2019-09-17T17:59:41+09:00 fluentd-test {"name":"wonyoung","salary":56000,"region":"seoul"}
tsv형태로 묶어서 gzip으로 저장되는 것으로 보인다. 맨 앞부터 utc time, topic, json형태의 data로 저장됨을 확인 할 수 있다. s3에 최종저장하는 방식으로 현재 gzip(default), json, text, lzo, lzma2, gzip_command가 지원되며, built-in variables를 통해 파일이름, directory이름에 %{hostname}, ${time_slice} 등 각종 날짜 등의 옵션을 지정할 수도 있다.
'빅데이터' 카테고리의 다른 글
| 스트림 프로세싱 with Faust - kafka consumer/producer (1) | 2019.11.21 |
|---|---|
| 데이터파이프라인이란 무엇인가? (0) | 2019.10.07 |
| AWS에서 공개한 Data validation library 소개 - Deequ (0) | 2019.09.27 |
| Fluentd vs Telegraf 차이점 알아보기 (0) | 2019.09.16 |
| (번역)Netflix에서 데이터를 통해 유연하고, 안전한 클라우드 인프라로 활용하는 방법 (253) | 2019.03.22 |
| [Stream Process as a Platform] Netflix의 실시간 스트림 처리 플랫폼 Keystone 소개 (251) | 2019.01.10 |



