
Github의 awslabs에서는 여러 aws관련(혹은 기타)관련 repository들을 opensource로 운영중에 있다.
- awslabs github url : https://github.com/awslabs
여기에 특별한, 보물같은 spark라이브러리를 최근에 facebook을 통해 찾았는데, 이름은 Deequ이다.
- deequ github url : https://github.com/awslabs/deequ
Deequ
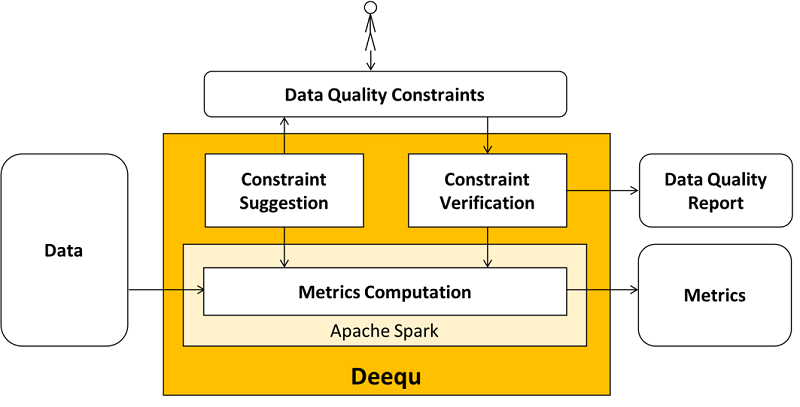
Deequ는 Apache Spark에서 돌아갈 수 있는 large dataset에 대해서 data기반의 unit test를 하여 data quality를 측정할 수 있는 라이브러리이다.
Deequ 적용 방법
Deequ는 Java8에서 Spark 2.2.x~2.4.x 에서 동작하는것을 보장한다.
<dependency>
<groupId>com.amazon.deequ</groupId>
<artifactId>deequ</artifactId>
<version>1.0.2</version>
</dependency>libraryDependencies += "com.amazon.deequ" % "deequ" % "1.0.2"Deequ 적용 예제
Deequ는 data를 특정 ETL 혹은 EDA 또는 머신러닝을 하기 전에 data에 존재하는 error를 사전에 잡아내기 위한 작업에 적합하다. 아래 example을 통해 어떻게 사용할 수 있을지 알아보자.
Deequ는 column/row 형태의 데이터에 적합하게 동작한다. 예를 들자면 csv file, database table, log 등 spark dataframe에 맞는 데이터이면 된다. 예를 들어 아래와 같이 Item이라고 불리는 데이터가 있다고 하자 해당 Item data에는 id, producetName 등 column이 존재한다.
case class Item(
id: Long,
productName: String,
description: String,
priority: String,
numViews: Long
)Deequ library는 Apache Spark에서 동작하도록 만들어졌으며 매우 많은양의 데이터(10억개 이상의 row)에서 동작하기 적합하게 만들어져 있다. 쉽게 설명하기 위해 아래와 같은 record들이 들어가 있다고 가정해서 이야기해보고자 한다.
val rdd = spark.sparkContext.parallelize(Seq(
Item(1, "Thingy A", "awesome thing.", "high", 0),
Item(2, "Thingy B", "available at http://thingb.com", null, 0),
Item(3, null, null, "low", 5),
Item(4, "Thingy D", "checkout https://thingd.ca", "low", 10),
Item(5, "Thingy E", null, "high", 12)))
val data = spark.createDataFrame(rdd)많은 data process application들은 읽어온 데이터에 대해 type을 가정하여 사용한다. 예를 들자면 해당 데이터는 boolean일거야, 라고 가정하거나 NULL이 존재하지 않는다고 가정하는 것이다. 하지만 이러한 가정이 깨지게 된다면 application은 crash가 발생할것이며 잘못된 output을 산출해낸다.
Deequ는 이러한 데이터를 data를 처리하기 전에 Unit-test를 해보자는 아이디어에서 나왔다. 만약 data에 이상이 있음이 확인되면 실제로 데이터를 처리하기 전에 해당 데이터들을 격리조치하거나 고칠 수 있다.
아래와 같은 data validation이 필요하다고 가정해보자.
(아주 까다롭지만 반드시 필요한 작업이라고 볼 수 있음)
- 데이터의 총 개수는 5개
- id에는 NULL이 존재하면 안되고 unique 해야한다.
- productName은 NULL이 존재하면 안된다
- priority는 high 혹은 low string으로 존재해야 한다
- numViews는 마이너스값이 존재하면 안된다
- 데이터의 반이상은 description에 url을 포함해야한다.
- numView의 평균값은 10보다 작거나 같아야한다.
상기와 같은 제한사항을 아래와 같이 code로 구성할 수 있다.
import com.amazon.deequ.VerificationSuite
import com.amazon.deequ.checks.{Check, CheckLevel, CheckStatus}
val verificationResult = VerificationSuite()
.onData(data)
.addCheck(
Check(CheckLevel.Error, "unit testing my data")
.hasSize(_ == 5) // we expect 5 rows
.isComplete("id") // should never be NULL
.isUnique("id") // should not contain duplicates
.isComplete("productName") // should never be NULL
// should only contain the values "high" and "low"
.isContainedIn("priority", Array("high", "low"))
.isNonNegative("numViews") // should not contain negative values
// at least half of the descriptions should contain a url
.containsURL("description", _ >= 0.5)
// half of the items should have less than 10 views
.hasApproxQuantile("numViews", 0.5, _ <= 10))
.run()상기와 같이 run()을 호출하고 나면 Deequ는 Spark job을 통해 data를 validation처리하고 그 결과를 아래와 같이 확인할 수 있다.
import com.amazon.deequ.constraints.ConstraintStatus
if (verificationResult.status == CheckStatus.Success) {
println("The data passed the test, everything is fine!")
} else {
println("We found errors in the data:\n")
val resultsForAllConstraints = verificationResult.checkResults
.flatMap { case (_, checkResult) => checkResult.constraintResults }
resultsForAllConstraints
.filter { _.status != ConstraintStatus.Success }
.foreach { result => println(s"${result.constraint}: ${result.message.get}") }
}아까 넣었던 값에 따라 아래와 같은 실행 결과를 확인할 수 있다.
We found errors in the data:
CompletenessConstraint(Completeness(productName)): Value: 0.8 does not meet the requirement!
PatternConstraint(containsURL(description)): Value: 0.4 does not meet the requirement!상기 에러구문을 해석하자면
- productName중 80%(5개 중 4개)가 non-null 이다.
- description중 40%(5개 중 2개)가 non-null이다.
운좋게 우리가 원하는 조건에 맞춰 data error를 찾을 수 있고, 누군가는(?) 이 데이터를 빠르게 고쳐야할것이다. ㅋㅋㅋㅋㅋ
(Fortunately, we ran a test and found the errors, somebody should immediately fix the data :))
참고 레퍼런스
'빅데이터' 카테고리의 다른 글
| 스트림 프로세싱 with Faust - Processors, Operations (0) | 2019.11.21 |
|---|---|
| 스트림 프로세싱 with Faust - kafka consumer/producer (1) | 2019.11.21 |
| 데이터파이프라인이란 무엇인가? (0) | 2019.10.07 |
| Fluentd로 데이터파이프라인 구축하기 kafka→kafka→s3 (1) | 2019.09.17 |
| Fluentd vs Telegraf 차이점 알아보기 (0) | 2019.09.16 |
| (번역)Netflix에서 데이터를 통해 유연하고, 안전한 클라우드 인프라로 활용하는 방법 (253) | 2019.03.22 |



